Loading... ## Hadoop简介 * Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构 * Hadoop是基于Java语言开发的,具有很好的跨平台特性,并且可以部署在廉价的计算机集群中 * Hadoop的核心是分布式文件系统HDFS(Hadoop Distributed File System)和MapReduce 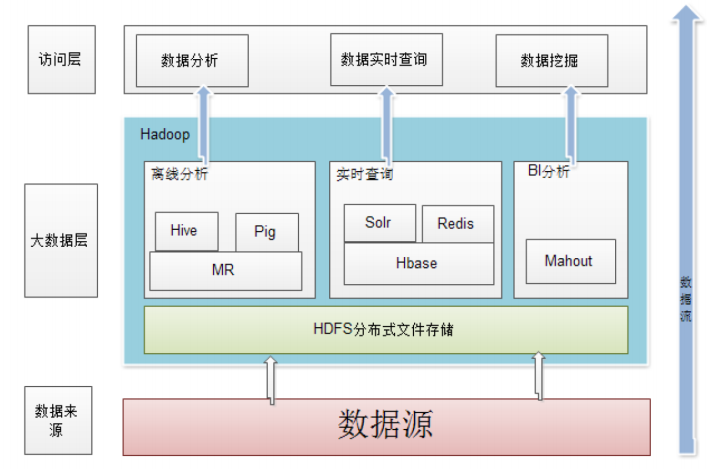 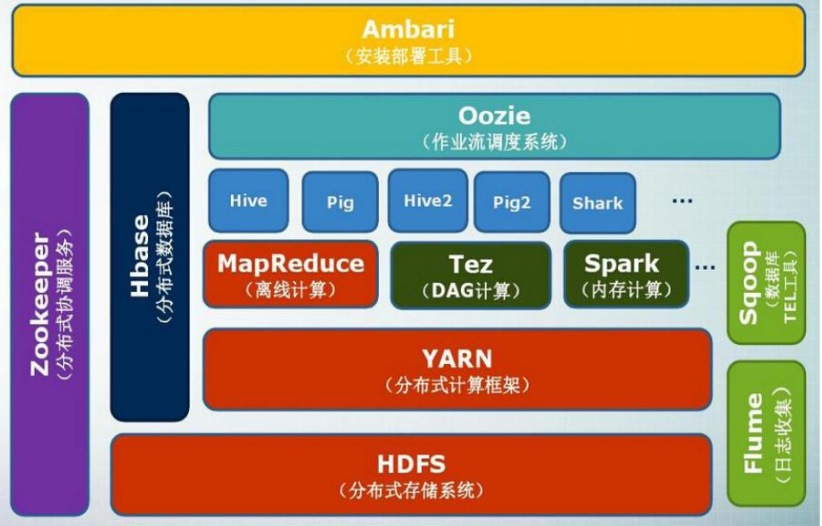  ## Hadoop的安装和使用 本文延续[\[Linux\]虚拟机CentOS7集群环境搭载](http://www.tangsong.fun/index.php/CentOS7.html),安装方式为**分布式模式**(使用多个节点构成集群环境来运行Hadoop) 注:分布式集群一般为三台服务器,一主二从。因为内存限制只选择一主一从,坐等内存条到货~ ### 相关配置 * VM最新版 * Centos7.7(CentOS-7-x86_64-DVD-1908.iso) * JDK8(jdk-8u221-linux-x64.rpm) * Hadoop3.2.1(hadoop-3.2.1.tar.gz) * 进入BIOS开启CPU的虚拟化 **注意**:Hadoop3.x只支持JDK8及以上版本 ### 搭载步骤 **零、创建Hadoop账户(非必须:伪分布式可以创建Hadoop帐号但是默认DataNode=1,如果集群还要在每台从节点创建Hadoop帐户,没必要)** 创建新用户:`sudo useradd –m hadoop –s /bin/bash` 设置密码:`sudo passwd hadoop` 增加管理员权限:`sudo adduser hadoop sudo` 切换用户:`sudo su hadoop` **一、Hadoop上传、解压、重命名、改权限、设置环境变量** * 上传:`cd /usr/local`<br>直接将下载好的 `hadoop-3.2.1.tar.gz`拖拽到SecureCRT,点击发送Zmodenm即可传输 * 解压:`sudo tar -zxf ./hadoop-3.2.1.tar.gz -C /usr/local` * 重命名:`sudo mv ./hadoop-3.2.1 hadoop` * 改权限(hadoop帐号):`sudo chown -R hadoop hadoop` * 环境变量:`vi /etc/profile` 末尾追加 ```Path export HADOOP_HOME=/usr/local/hadoop export PATH=$HADOOP_HOME/bin:$PATH ``` * 刷新环境变量:`source /etc/profile` **二、配置Hadoop(MapReduce)文件 `/usr/local/hadoop/etc/hadoop`(共7个)** 1.workers(2.x中为salves!),配置从节点 ```Hadoop centos02 ``` 2.hadoop-env.sh,末尾配置JAVE_HOME ```Hadoop export HADOOP_IDENT_STRING=$USER export JAVA_HOME=/usr/java/jdk1.8.0_221-amd64 ``` 3.yarn-env.sh,末尾配置JAVE_HOME ```Hadoop export JAVA_HOME=/usr/java/jdk1.8.0_221-amd64 ``` 4.core-site.xml ```Hadoop <configuration> <!--hdfs --> <property> <name>fs.defaultFS</name> <value>hdfs://centos01:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/usr/local/hadoop/temp</value> </property> </configuration> ``` * `hadoop.tmp.dir`表示存放临时数据的目录,即包括 `NameNode`的数据,也包括 `DataNode`的数据。该路径任意指定,只要实际存在该文件夹即可 * `name`为 `fs.defaultFS`的值,表示 `hdfs`路径的逻辑名称 5.hdfs-site.xml(3.x版本端口号已从50070改为9870!) ```Hadoop <configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>centos01:50090</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/hadoop/centos01/dfs/name</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/hadoop/centos01/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration> ``` * `dfs.namenode.secondary.http-address`虚拟机访问namedode地址,**设置成50090但是访问还是9870,若直接设置成9870会导致端口占用无法启动SecondaryNameNode** * `dfs.namenode.name.dir`表示名称节点的元数据保存目录和数据节点的数据保存目录,也可以把 `data`分开放在 `dfs.datanode.data.dir`中 **【注意】:若是后期更改需要删除掉 `/usr/hadoop/centos01/dfs/name`下的current,再把 `/usr/local/hadoop/temp/dfs/namesecondary`底下的current拷贝到刚才的name目录下,格式化NameNode即可** * `dfs.replication`表示冗余备份节点的个数=**从节点**的个数 * `dfs.webhdfs.enabled`开启浏览器访问 * `dfs.permissions`关闭权限拦截(仅学习时用) 6.mapred-site.xml ```Hadoop <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>centos01:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>centos01:19888</value> </property> </configuration> ``` * mapred和yarn在最终运行时会合并,YARN为Hadoop2.0演变,在HDFS之上,接着才是MapReduce和Others * `mapreduce.framework.name`设置MapReduce运行模式yarn集群/local本地 * `mapreduce.jobhistory.address`通过主机地址查看MapReduce历史记录 * `mapreduce.jobhistory.webapp.address`通过浏览器查看MapReduce历史记录 7.yarn-site.xml ```Hadoop <configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreuce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>centos01:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>centos01:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>centos01:8035</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>centos01:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>centos01:8088</value> </property> </configuration> ``` * `yarn.nodemanager.aux-services`配置Map和Reduce的中间产物shuffle阶段 * `yarn.nodemanager.aux-services.mapreuce.shuffle.class`配置shuffle阶段实现的处理类/机制 * `yarn.resourcemanager.address`配置资源管理器地址默认端口号8032,以下为其细节组件 * `yarn.resourcemanager.scheduler.address`资源调度框架 * `yarn.resourcemanager.resource-tracker.address`资源追踪 * `yarn.resourcemanager.admin.address`管理者 * `yarn.resourcemanager.webapp.address`浏览器访问resourcemanager ### 超级管理员root启动Hadoop 1.文件配置5中 `dfs.permissions`关闭权限拦截(仅学习时用) 2.在/hadoop/sbin路径下: 将start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数 ```Hadoop HDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root ``` 3.start-yarn.sh,stop-yarn.sh顶部也需添加以下: ```Hadoop YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root ``` ### 以上主节点的配置完成,将配置完毕的Hadoop远程分发给其它子节点 1. `cd /usr/local` 2. `scp -r hadoop/ root@centos02:/usr/local/` 3. 同上,追加环境变量:`vi /etc/profile` :末尾追加 ```Path export HADOOP_HOME=/usr/local/hadoop export PATH=$HADOOP_HOME/bin:$PATH ``` * 刷新环境变量:`source /etc/profile` ### 验证HDFS 一、格式化:`bin/hdfs namenode -format`<br>重启主节点计算机:`reboot`<br>`cd /usr/local/hadoop` 二、启动:`sbin/start-dfs.sh` 三、检查: (1)查看jps进程 centos01: ```jps 3633 SecondaryNameNode 3364 NameNode 3796 JPS ``` centos02: ```jps 25138 DataNode 25242 JPS ``` (2)查看浏览器 虚拟机访问 `centos01:9870` (3)通过命令查案状态 `bin/hdfs dfsadmin -report` (4)关闭 `sbin/stop-dfs.sh` --- ## 写在最后 摸着石头过河的日子,走一步有走一步的险,但是却锻炼了脚力。Hadoop网上很杂,而且像老师说的很多文章都没有标明自己的版本号,两者差异很大,老的版本有老版本的稳定,新版本有新版本的特性。之前有老师说小公司追求的就是稳定的实现功能,能运行就好了。大公司才会去考虑优化,而且接盘的大部分都是老版本改的。所以最好的方法就是啃官方文档,学习最前沿的技术总是有好处的。 Last modification:August 11, 2022 © Allow specification reprint Like 0 喵ฅฅ
3 comments
膜拜大佬!
很棒!
Thanks