Loading... ## HDFS简述 HDFS(Hadoop Distributed File System),作为Google File System(GFS)的实现,是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开发的,可以运行于廉价的商用服务器上。 <!--more--> 它所具有的高容错、高可靠性、高可扩展性、高获得性、高吞吐率等特征为海量数据提供了不怕故障的存储,为超大数据集(Large Data Set)的应用处理带来了很多便利。 ### 特点 ●兼容廉价的硬件设备 ●流数据读写 ●大数据集 ●简单的文件模型 ●强大的跨平台兼容性 ### 局限性 ●不适合低延迟数据访问 ●无法高效存储大量小文件 ●不支持多用户写入及任意修改文件 ## HDFS架构 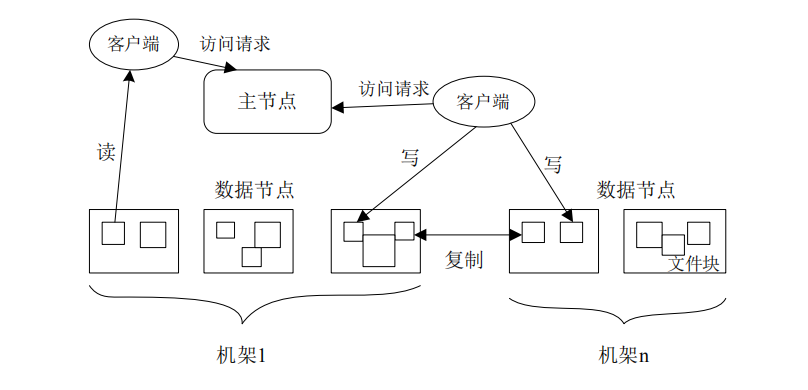  HDFS由四部分组成,`HDFS Client`、`NameNode`、`DataNode`和 `Secondary NameNode`。 HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群包括一个名称节点(NameNode)和若干个数据节点(DataNode)。名称节点作为中心服务器,负责管理文件系统的命名空间及客户端对文件的访问。集群中的数据节点一般是一个节点运行一个数据节点进程,负责处理文件系统客户端的读/写请求,在名称节点的统一调度下进行数据块的创建、删除和复制等操作。每个数据节点的数据实际上是保存在本地Linux文件系统中的。 ### HDFS的数据流(面试重点) 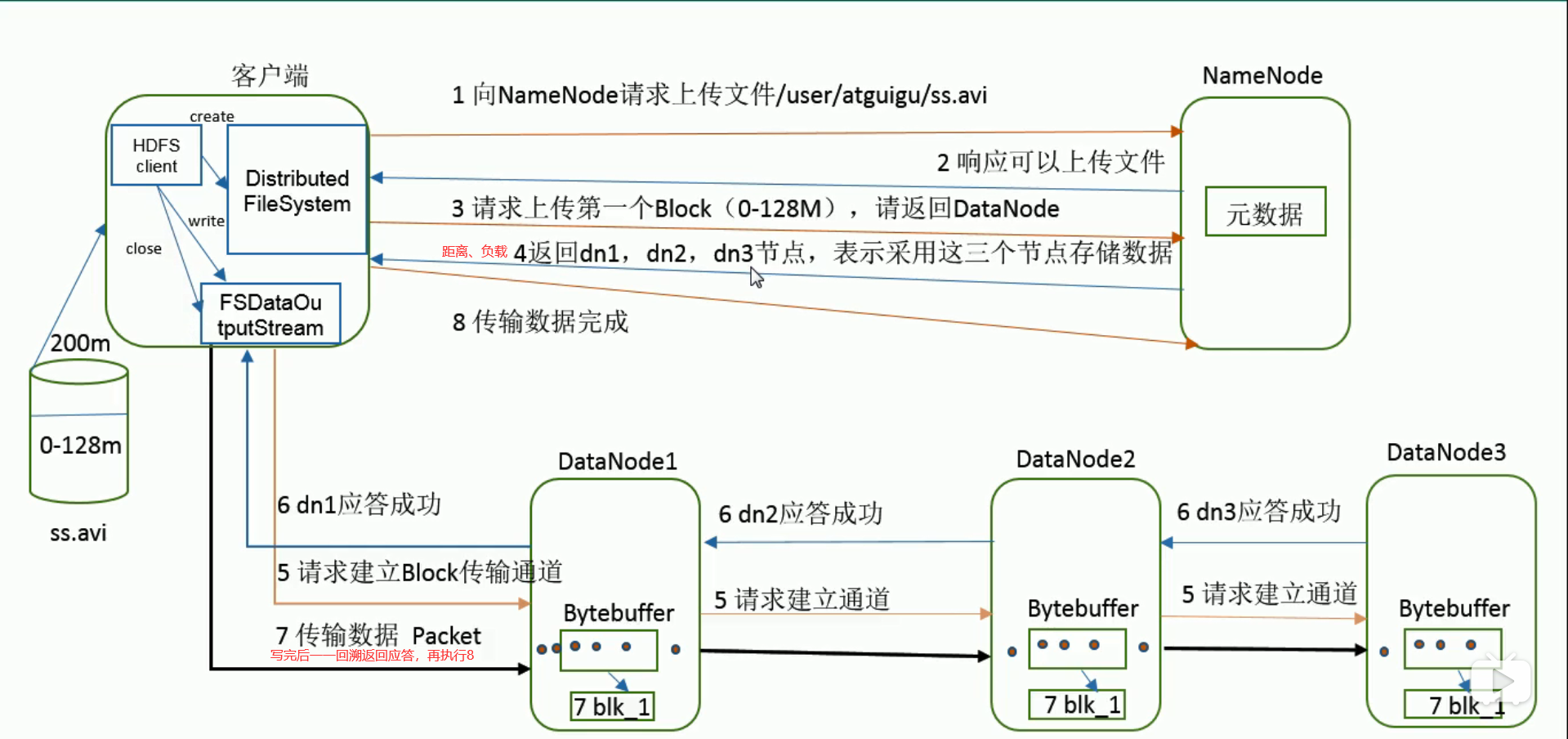 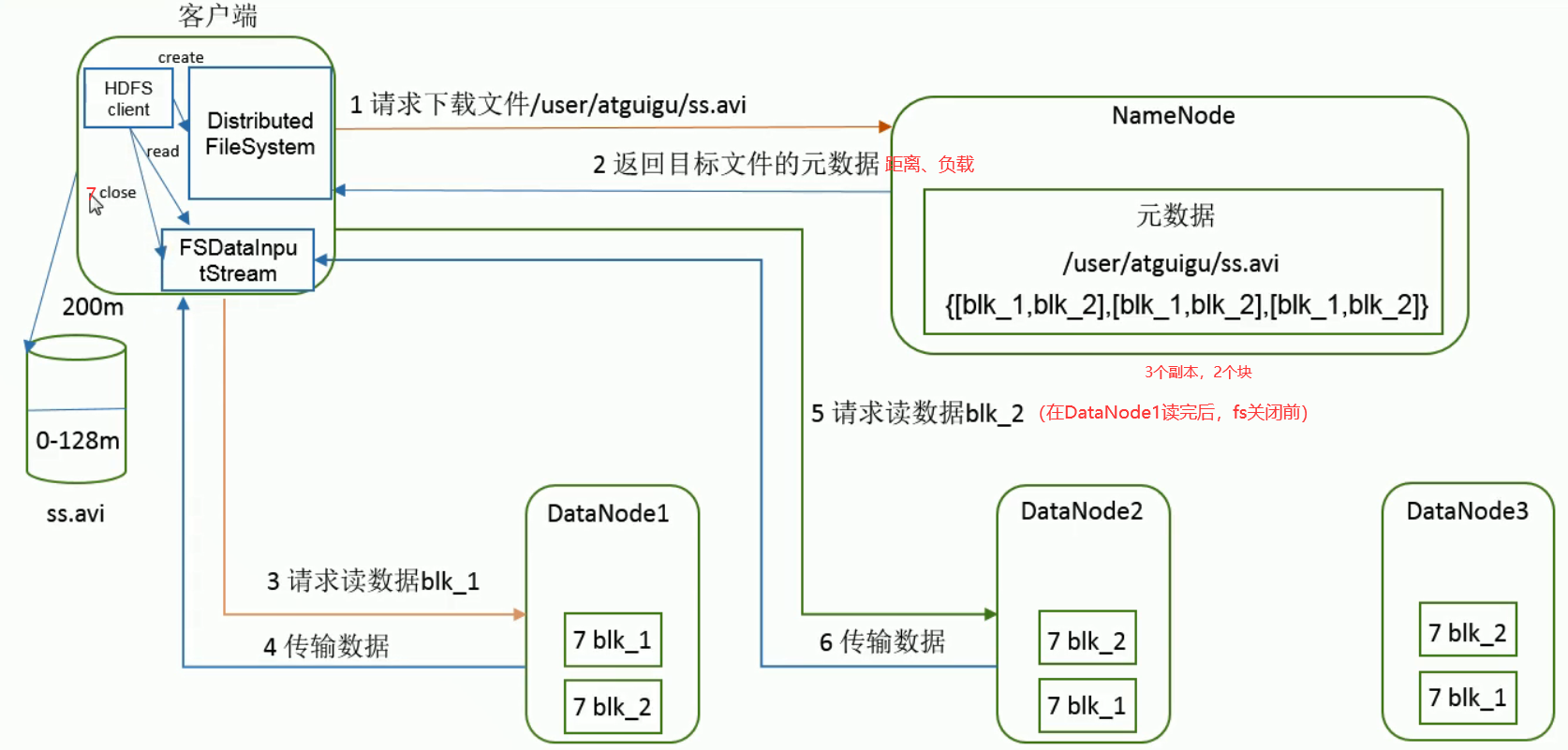 ### 网络拓扑-节点距离计算 **节点距离:两个节点到达最近的共同祖先的距离总和。** 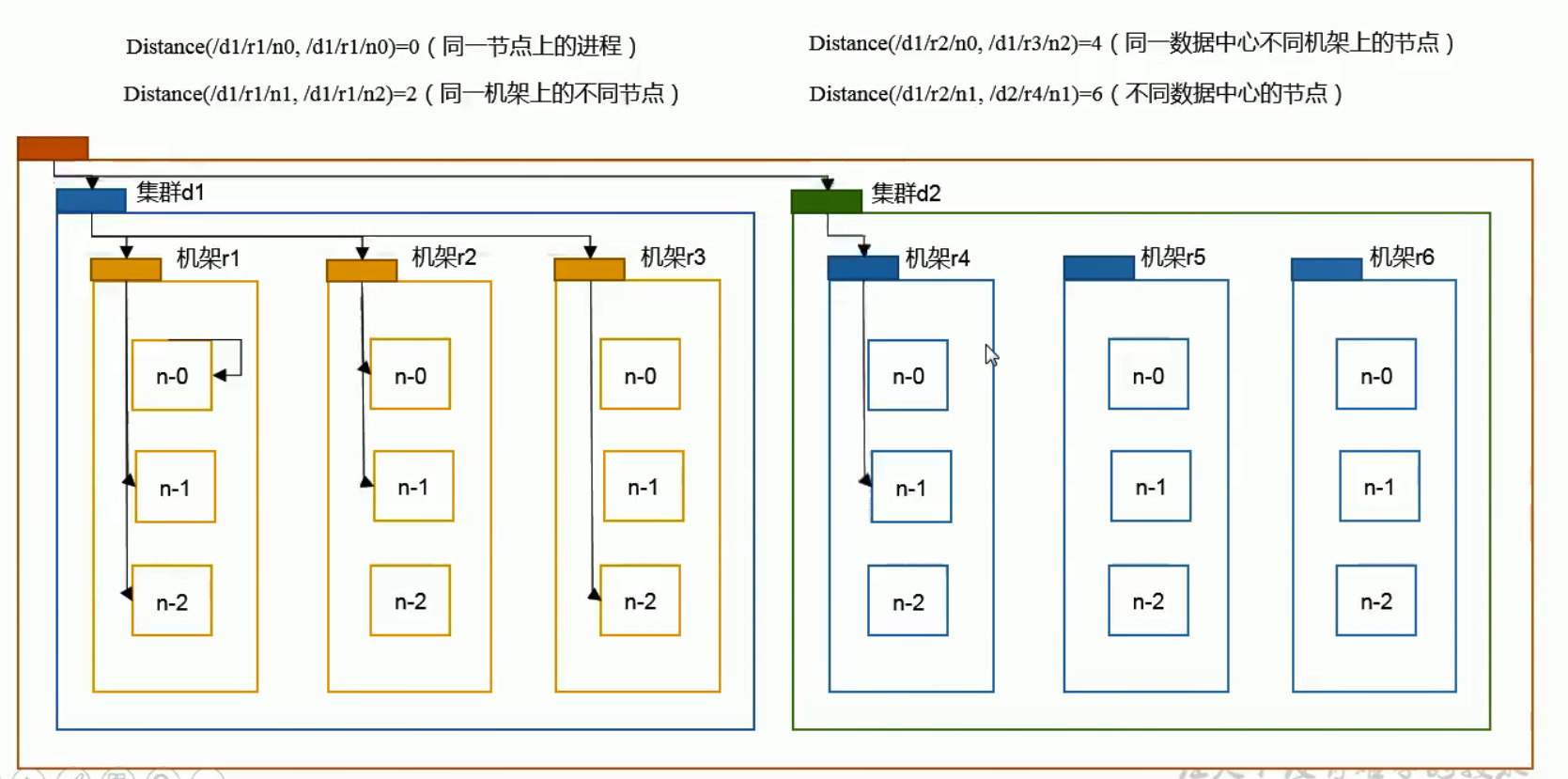 ### HDFS客户端:就是客户端。 1、提供一些命令来管理、访问 HDFS,比如启动或者关闭HDFS。 2、与 DataNode 交互,读取或者写入数据;读取时,要与 NameNode 交互,获取文件的位置信息;写入 HDFS 的时候,Client 将文件切分成 一个一个的Block,然后进行存储。 ### NameNode:(面试重点) 1、负责管理分布式文件系统的命名空间(Namespace) 2、保存了两个核心的数据结构,即FsImage(**镜像**)和EditLog(**日志**) * FsImage:NameNode内存中元数据序列化后形成的文件。 * Edits:记录客户端更新元数据信息的每一步操作(可通过Edits运算出元数据) 3、记录了每个文件中各个块(Block 64M)所在的数据节点的位置信息 4、配置副本策略 5、处理客户端读写请求。 ### Secondary NameNode:(面试重点) **并非 NameNode 的热备。当NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务。它是用来保存名称节点中对HDFS 元数据信息的备份,并减少名称节点重启的时间。SecondaryNameNode一般是单独运行在一台机器上** 1、辅助 NameNode,分担其工作量。 2、定期合并 fsimage和fsedits,并推送给NameNode。 3、在紧急情况下,可辅助恢复 NameNode。 #### NN和2NN工作机制   **oiv查看Fsimage文件** `hdfs oiv -p XML -i fsimage_0000000000000000025 -o /opt/module/hadoop-2.7.2/fsimage.xml` (hdfs oiv -p 文件类型 -i镜像文件 -o 转换后文件输出路径) ** oev查看Edits文件** `hdfs oev -p XML -i edits_0000000000000000012-0000000000000000013 -o /opt/module/hadoop-2.7.2/edits.xml` (hdfs oev -p 文件类型 -i编辑日志 -o 转换后文件输出路径) **hdfs-default.xml(Hadoop3.x后直接放在hdfs-site.xml)设置CheckPoint** ```XML <property> <name>dfs.namenode.checkpoint.period</name> <value>3600</value> <description>SecondaryNameNode每隔一小时执行一次</description> </property> <property> <name>dfs.namenode.checkpoint.txns</name> <value>1000000</value> <description>操作动作次数</description> </property> <property> <name>dfs.namenode.checkpoint.check.period</name> <value>60</value> <description> 1分钟检查一次操作次数</description> </property > ``` ### DataNode: 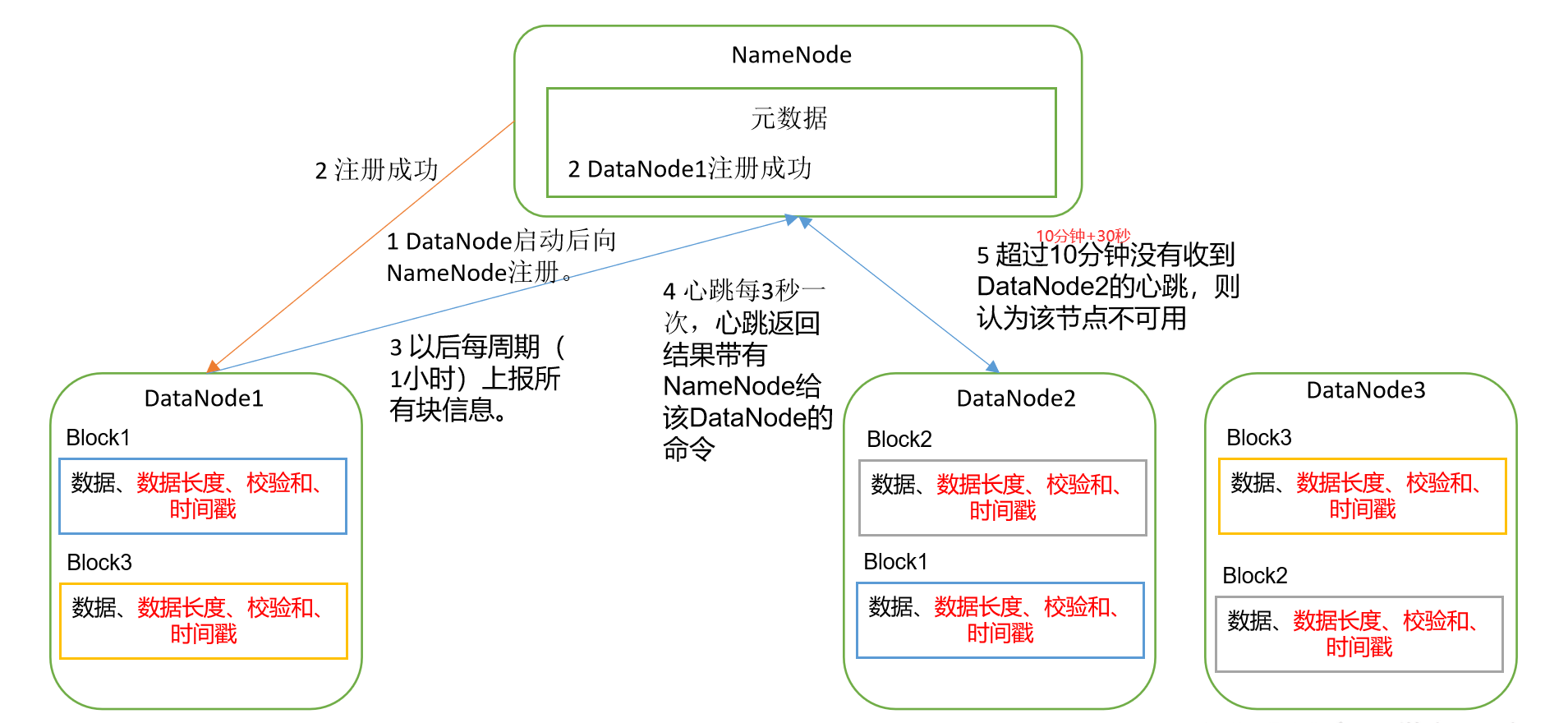 **NameNode 下达命令,DataNode 执行实际的操作。** 1、存储实际的数据块。 2、执行数据块的读/写操作。 ## HDFS存储原理 ### 冗余数据存储 作为一个分布式文件系统,为了保证系统的容错性和可用性,HDFS采用了多副本方式对数据进行冗余存储,通常一个数据块的多个副本会被分布到不同的数据节点上。 优点: (1)加快数据传输速度 (2)容易检查数据错误 (3)保证数据可靠性 ### 数据存取策略 #### 数据存放 * 第一个副本:放置在上传文件的数据节点;如果是集群外提交,则随机挑 选一台磁盘不太满、CPU不太忙的节点 * 第二个副本:放置在与第一个副本不同的机架的节点上 * 第三个副本:与第一个副本相同机架的其他节点上 * 更多副本:随机节点 一般情况下副本系数为3,这种方式减少了机架间的写流量,从而提高了写的性能。机架故障的机率远小于节点故障。这种方式并不影响数据可靠性和可用性的限制,并且它确实减少了读操作的网络聚合带宽,因为文件块仅存在两个不同的机架,而不是三个。 #### 数据读取 * HDFS提供了一个API可以确定一个数据节点所属的机架ID,客户端也 可以调用API获取自己所属的机架ID * 当客户端读取数据时,从名称节点获得数据块不同副本的存放位置列表,列表中包含了副本所在的数据节点,可以调用API来确定客户端和这些数据节点所属的机架ID,当发现某个数据块副本对应的机架ID和客户端对应的机架ID相同时,就优先选择该副本读取数据,如果没有发现,就随机选择一个副本读取数据 #### 流水线复制 假设HDFS副本系数为 `3`,当本地暂时文件积累到一个数据块大小时,`client`会从 `NameNode`获取一个列表用于存放副本。然后 `client`开始向第一个 `DataNode`数据传输,第一个 `DataNode`一小部分一小部分地接收数据,将每一部分写入本地仓库,并同一时间传输该部分到列表中的第二个 `DataNode`节点。第二个 `DataNode`也是这样,一小部分一小部分地接收数据,写入本地仓库,并同一时候转发给下一个节点,数据以流水线的方式从前一个 `DataNode`拷贝到下一个 `DataNode`。最后,第三个 `DataNode`接收数据并存储到本地。因此,`DataNode`能**流水线地从前一个节点接收数据,并同一时间转发给下一个节点**,数据以流水线的方式从前一个 `DataNode`拷贝到下一个 `DataNode`,并以相反的方向 `Ack`前一个 `Node`。 ## 数据错误与恢复 **1.名称节点出错** 名称节点保存了所有的元数据信息,其中,最核心的两大数据结构是FsImage和Editlog,如果这两个文件发生损坏,那么整个HDFS实例将失效。因此,HDFS设置了备份机制,把这些核心文件同步复制到备份服务器SecondaryNameNode上。当名称节点出错时,就可以根据备份服务器SecondaryNameNode中的FsImage和Editlog数据进行恢复 **2.数据节点出错** •每个数据节点会定期向名称节点发送“心跳”信息,向名称节点报告自己的状态 •当数据节点发生故障,或者网络发生断网时,名称节点就无法收到来自一些数据节点的心跳信息,这时,这些数据节点就会被标记为“宕机”,节点上面的所有数据都会被标记为“不可读”,名称节点不会再给它们发送任何I/O请求 •这时,有可能出现一种情形,即由于一些数据节点的不可用,会导致一些数据块的副本数量小于冗余因子 •名称节点会定期检查这种情况,一旦发现某个数据块的副本数量小于冗余因子,就会启动数据冗余复制,为它生成新的副本 •HDFS和其它分布式文件系统的最大区别就是可以调整冗余数据的位置 **3.数据出错** •网络传输和磁盘错误等因素,都会造成数据错误 •客户端在读取到数据后,会采用md5和sha1对数据块进行校验,以确定读取到正确的数据 •在文件被创建时,客户端就会对每一个文件块进行信息摘录,并把这些信息写入到同一个路径的隐藏文件里面 •当客户端读取文件的时候,会先读取该信息文件,然后,利用该信息文件对每个读取的数据块进行校验,如果校验出错,客户端就会请求到另外一个数据节点读取该文件块,并且向名称节点报告这个文件块有错误,名称节点会定期检查并且重新复制这个块 Last modification:August 11, 2022 © Allow specification reprint Like 0 喵ฅฅ