Loading... [Java成神之路](https://hollischuang.gitee.io/tobetopjavaer/#/menu) 虽然目前只有基础篇,但是对于打地基来说可以算是典中典了,另外也出了实体书,有能力的话还是可以支持下的。 ## 一、面向对象 ### 1、面向对象和面向过程 **面向过程是自顶向下的编程模式。**主要是把问题拆分成一个个步骤,每个步骤用函数实现。总之不要问为什么,上来先反手一个函数定义就完事了。例如实现各种排序等等。 **面向对象是将事务高度抽象化的编程模式。**同样是要把问题拆分成一个个步骤,但是把每个步骤都抽象成对象,基于不同对象以及对象的能力进行业务逻辑的组合实现。例如造车,把车的各个部件定义成属性,然后在把车抽象成一个Car类。 举一个栗子:要设计一个象棋。 **面向过程:**重点在于怎么实现每一步(的函数)“开始—黑走—棋盘—白走—棋盘—判断—循环” **面向对象:**重点在于各司其职。黑白双方对象负责演算,棋盘对象负责画布,规则对象负责判断。这样优势在于不用重复造轮子,一次创建,多次使用。 所以,面向过程占用资源相对低,速度相对快。而面向对象刚好相反。 ### 2、面向对象的三大特性和五大基本原则 三大特性**封装(Encapsulation)**、**继承(Inheritance)**、**多态(Polymorphism)**就不在多赘述了。 稍微提一句: 我认为,多态应该是一种**运行期**特性,Java 中的重写是多态的体现。不过也有人提出重载是一种静态多态的想法,这个问题在 StackOverflow 等网站上有很多人讨论,但是并没有什么定论。我更加倾向于重载不是多态。(可以看下文的第3点) 重点介绍以下五大基本原则: * **单一职责原则(Single-Responsibility)**:一个类最好只做一件事,只有一个引起它的变话。 职责多变化就多,职责依赖也多,就会产生影响,从而损伤内聚性和耦合度。 * **开放封闭原则(Open-Closed)**:对扩展开放,对修改封闭。 其核心思想就是对抽象编程,而不对具体编程。因为抽象相对稳定,让类依赖于固定的抽象,所以修改就是封闭的;而通过面向对象的继承和多态机制,又可实现对抽象类的继承,通过覆写其方法来改变固有行为,实现新的拓展方法,所以就是开放的。 * **Liskov 替换原则(Liskov-Substitution)**:子类必须能够替换其基类,从而在运行期内能够识别子类。是保证继承复用的基础。 Liskov 替换原则能够保证系统具有良好的拓展性,同时实现基于多态的抽象机制,能够减少代码冗余,避免运行期的类型判别。 * **依赖倒置原则(Dependecy-Inversion)**:高层模块不依赖于底层模块,二者都同依赖于抽象;抽象不依赖于具体,具体依赖于抽象。依赖于抽象,就是对接口编程,不要对实现编程。 即MVC的分层思想:在依赖之间定义一个抽象的接口(`Service`)使得高层模块(`Controller`)调用接口,而底层模块(`ServiceImpl`)实现接口的定义,以此来有效控制耦合关系,达到依赖于抽象的设计目标。 * **接口隔离原则(Interface-Segregation)**:使用多个小而专门的接口,而不要使用一个大的总的接口。 即,接口应该内聚,避免“胖”接口。业务中可以用多重继承分离方法,通过接口多继承来实现客户的需求。 ### 3、重载(Overloading)和重写(Overriding) 两者的概念和区别在之前的《Java就业面试题大全》的17中都有体现,其中还有一题华为的面试题:**为什么函数不能根据返回类型来区分重载?** 这里从不同**周期**的角度来区分它们: 1. 重载是一个编译器概念,重写是一个运行期间的概念。 2. 重载遵循所谓的“编译期绑定”,即在编译时根据参数变量的类型判断应该调用哪个方法。 3. 重写遵循所谓的“运行期绑定”,即在运行的时候,根据引用变量所指向的实际对象的类型来调用方法。 4. 因为编译期已经确定调用哪个方法,所以重载并不是多态。而重写是多态。重载是一种语言特性,是一种语法规则,与多态无关,与面向对象也无关。 ### 4、Java如何实现的平台无关性的 无关性其实就是独立性,在今年的4399笔试题里面也遇到过这题:**如何理解java平台的独立性?**,当时主要是从体系结构无关和可移植两方面来说明。今天就重新再认识认识。 无关性,或者说独立性。就是一种语言在计算机上的运行不受平台约束,一次编译,到处执行(`Wrete One, Run Anywhere`)。往细的来说,就是用Java创建的可执行二进制程序,能够不加改变的运行于多个平台。因此可以运行在各种嵌入式设备上(打印机、扫描仪等),好处也就不言而喻。 虽然 Java 语言是平台无关的,但**JVM虚拟机** 却是平台有关的,不同的操作系统上面要安装对应的 JVM。 Java 虚拟机充当了桥梁,将 Class 文件转成对应平台的二进制文件等,从而屏蔽了底层操作系统和硬件的差异。 而所有Java 文件都要编译成统一的 **Java Class 文件**,它可以在任意平台创建并被平台的Java 虚拟机装载并执行,从而实现了平台的无关性。 再者**Java语言规范**通过规定 Java 语言中基本数据类型的取值范围和行为在所有平台的一致性,为平台无关性提供强了有力的支持。 当然,如今JVM虚拟机已经可以支持很多Java以外的语言了,如**Kotlin**、**Groovy**、JRuby、Jython、**Scala**等 ### 5、为什么说Java中只有值传递 值传递还是引用传递,最主要区别就是是直接传递的,还是传递的是一个副本。 Java中其实是**共享对象传递**,**它是值传递的一种特例**,主要是把对象的引用当做值传递给方法。 如果修改引用,是不会对原来的对象有任何影响的,但是如果直接修改共享对象的属性的值,是会对原来的对象有影响的。 就好比**家(钥匙)**方法中,你复制了一把家里的钥匙给你朋友,你朋友通过复制的钥匙进去你家,把你家砸了,那你回去的时候会发现家真的被砸了。。。但是如果你朋友把这把复制的钥匙改造成他家的钥匙,就算他把他家给点了也是不会影响到你的钥匙和家的。 --- ## 二、Java语言基础 ### 1、Java中的关键字 #### `transient` transient变量修饰符。被 transient 修饰的成员变量,在序列化的时候其值会被忽略,在被反序列化后,transient 变量的值被设为初始值, 如 int 型的是 0,对象型的是 null。 #### `instanceof` 测试它左边的对象是否是它右边的类的实例,返回 boolean 的数据类型。 如:`str instanceof String ? true : false` #### `volatile` 在很早的一篇《Java线程详解》中,我就记录过关于volatile相关的说明,这里再更规范的学习一遍。(估计这边看完今天又得歇菜了) volatile一般被比喻成“轻量级的synchronized”,但它只能用来修饰变量,无法修饰方法以及代码块。只需要在一个可能被多线程访问的变量上使用 `volatitle`修饰即可。 * **可见性** 如果一个变量被 volatile 所修饰的话,在每次数据变化之后,其值都会被强制刷入主存。而其他处理器的缓存由于遵守了缓存一致性协议,也会把这个变量的值从主存加载到自己的缓存中。这就保证了一个 volatile 在并发编程中,其值在多个缓存中是可见的。<br>(也可以理解成当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。) 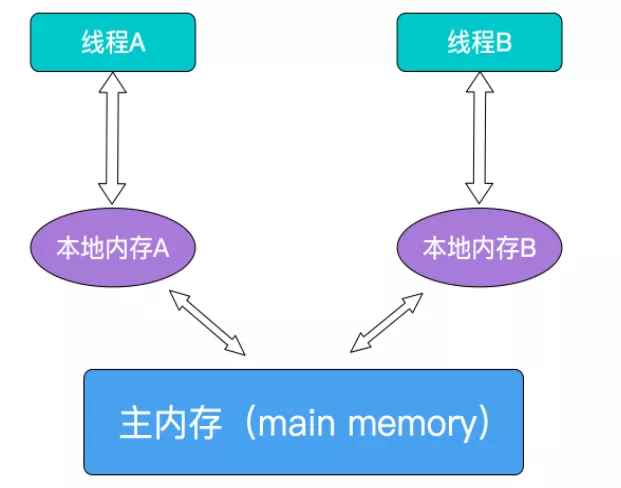 * **有序性** volatile可以禁止**指令重排优化**,确保代码按顺序执行。 * **(不具备)原子性** 原子性就是要么操作内容都执行,要么都不执行。如时间片的轮换就可能出现原子性问题。保证原子性需要通过字节码指令 `monitorenter`(加锁)和 `monitorexit`(放锁)。但是volatile和这两个没有半毛钱关心。 #### `synchronized` synchronized就满足了可见性、有序性(但是无法禁止指令重排和处理器优化)和原子性三种特性。它既可以修饰方法也可以修饰代码块。 它是借助Monitor实现的,并且由于对它不断的进行优化,出现了很多种类型的锁:重量级锁、轻量级锁、偏向锁、锁消除、适应性自旋锁、锁粗化等等。在之前的《java线程详解》中有提及一部分,也可以参考这里的: [Java虚拟机的锁优化技术](https://www.hollischuang.com/archives/2344) #### `final` 面试笔试中常拿来与finally, finalize做区别 * `final` 用于声明属性,方法和类,分别表示**属性不可变,方法不可覆盖,类不可继承**。内部类要访问局部变量,局部变量必须定义成final类型. * `finally` 是异常处理语句结构的一部分,表示总是执行。 * `finalize` 是Object类的一个方法,在垃圾收集器执行的时候会调用被回收对象的此方法,可以覆盖此方法提供垃圾收集时的其他资源回收,例如关闭文件等。该方法是一个回调方法,不需要我们主动调用。 #### `static` Java 中共有三种变量,分别是类变量、成员变量和局部变量。他们分别存放在 JVM的方法区、堆内存和栈内存中。 而static可以修饰成员变量和方法,也可以形成静态代码块,或者静态嵌套类,但是没啥用。 对于变量和方法,会提升到JVM的方法区;而静态块常用于初始化类的静态变量。大多时候还用于在类装载时候创建静态资源(只在类装载入内存时执行一次);至于静态嵌套类,则只是为了便于项目打包(不能用于嵌套的顶层)。 #### `const` java预留关键字,卑微的存在感,几乎不用。 ### 2、String 一旦一个 string 对象在内存(堆)中被创建出来,他就无法被修改。特别要注意的是,String 类的所有方法都没有改变字符串本身的值,都是返回了一个新的对象。(这点面试官常问) 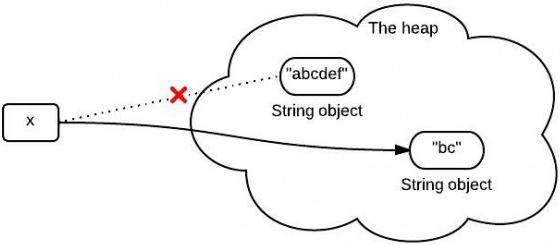 如果你需要一个可修改的字符串,应该使用 StringBuffer 或者 StringBuilder。否则会有大量时间浪费在垃圾回收上,因为每次试图修改都有新的 string 对象被创建出来。(实际开发中POJO中实体类的优化就需要这么做) #### String对 `+`的重载以及其它拼接方式 `String s = "a" + "b"`,因为两个变量都是编译器常量,所以会被编译器进行常量折叠成 `String s = "ab"` (注意,Java是不支持运算符重载的,这里的 `+`只是Java提供的一个语法糖) 而 `String s = "a" + str`要用StringBulider/StringBuffer的append()方法替代,最后在用toString()方法。这样才是最优解(底层就是一个new String())。 StringBuffer线程安全 和 StringBuilder线程不安全,但是快 这里还引申出华为的一道面试题:**什么情况下用“+”运算符进行字符串连接比调用 StringBuffer/StringBuilder对象的 append 方法连接字符串性能更好?** 解析:[《Java面试宝典Beta5.0》题4.1](http://www.tangsong.fun/index.php/JavaTest2-1.html) 当然还可以用String类中的 `concat`方法,但是没必要。`String newStr = str1.concat("-").concat(str2)` 顺带一提,JDK8中的String还提供了join方法更好的来处理字符串数组或者列表的拼接,这里就不再演示。 **耗时比较:** **`StringBuilder<StringBuffer<concat<+<StringUtils.join`** **总体来说,**如果不是循环体中的字符串拼接,直接用 `+`就行了不用太多花里胡哨。如果是并发中就用 `StirngBuffer` #### `substring(int beginIndex, int endIndex)`截取字符串并返回 按index来算的话,它的区间是 `[beginIndex, endIndex)` ```Java String x = "abcdef"; x = x.substring(1,3); System.out.println(x); bc ``` **版本问题** **JDK6**中String类中包含三个成员变量:字符数组 `char value[]`、数组第一位索引 `int offset`、字符个数 `int count`。 而当用了substring时新生成的String对象指向的是堆中同一个数组,只是count和offset的值改变了。这使得如要对一段很长的字符串切割很小的一部分,但却一直引用了整个很长的字符串,导致它无法被回收,可能存在内存泄露。 ```Java public String substring(int beginIndex, int endIndex) { //check boundary return new String(offset + beginIndex, endIndex - beginIndex, value); } ``` **JDK7** 中,substring 方法会在堆内存中创建一个新的数组。使用 new String 创建了一个新字符串,避免对老字符串的引用。从而解决了内存泄露问题。 ```Java public String substring(int beginIndex, int endIndex) { //check boundary int subLen = endIndex - beginIndex; return new String(value, beginIndex, subLen); } ``` #### replaceFirst 、 replaceAll 、 replace 区别 replace全家桶都(没有replaceLast)是字符替换方法,主要用来替换文字、符合正则的数据、HTML标签等。 ```Java //replace() System.out.println("abac".replace("a", "\a")); //\ab\ac //replaceAll() Pattern pattern = Pattern.compile("正则表达式"); Matcher matcher = pattern.matcher("正则表达式 Hello World,正则表达式 Hello World"); System.out.println(matcher.replaceAll("Java")); //Java Hello World,Java Hello World //replaceFirst() Pattern pattern = Pattern.compile("正则表达式"); Matcher matcher = pattern.matcher("正则表达式 Hello World,正则表达式 Hello World "); System.out.println(matcher.replaceFirst("Java")); //Java Hello World,正则表达式 Hello World ``` #### switch的String支持 对String的支持是Java7开始的新特性。底层是通过比较HashCode()和equals()方法实现的。 样例可以参考这里:[《java就业面试大全》第5题](http://www.tangsong.fun/index.php/JavaTest1.html) #### String有没有长度限制? 别说,还真有。 在编译期,要求字符串常量池中的常量不能超过 65535,并且在 javac 执行过程中控制了最大值为 65534。 在运行期,长度不能超过 Int 的范围,否则会抛异常。 ### 3、常量池 Java中三大常量池:**字符串常量池**、**Class常量池**、**运行时常量池** #### 字符串(常量)池 通过 `字面量`形式创造出来的字符串 `String str = "abc"`, JVM 中,为了减少相同的字符串的重复创建,为了达到节省内存的目的。会单独开辟一块内存,用于保存字符串常量,这个内存区域被叫做字符串常量池。 当代码中出现双引号形式(字面量)创建字符串对象时,JVM 会先对这个字符串进行检查,如果字符串常量池中存在相同内容的字符串对象的引用,则将这个引用返回;否则,创建新的字符串对象,然后将这个引用放入字符串常量池,并返回该引用。 (String的intern同理) 这叫做**字符串驻留**或**池化**。 JDK7之前,字符串常量池存放在**永久代**中;JDk7中移到了**堆内存**中;JDK8开始元空间替代了永久代,所以移到了**元空间**中。(运行时常量池也是这样的) #### Class常量池 Class常量池中主要存放两大类常量:**字面量**(只能是右值)和**符号引用**(类和接口的全限定名/字段的名称和描述符/方法的名称和描述符) Class常量池主要就是用来保存常量的一个媒介场所,并且是一个中间场所。在 JVM 真的运行时,需要把常量池中的常量加载到内存中。从而进入运行时常量池。 #### 运行时常量池 被分配在JVM的方法区之中,是类或接口的常量池的运行时表示形式。 ### 4、自动拆/装箱的实现 这里先要了解一点:基本数据类型的变量不需要new创建,因此它们不会在堆上创建,而是直接在栈内存中存储,所以会更加高效。 而因为集合类中不能放基本类型,容器要求的元素必须是Object类型。所以也就要有八大包装类,好让基本类型也有对象的性质,并且添加了属性与方法去丰富基本类型的操作。 我们所说的装箱就是把基本数据类型转成包装类型,而拆箱则相反。 当然Java5开始就有了自动装箱、自动拆箱。如: 把基本数据类型放入集合类中的时候,会进行自动装箱;而包装类之间的运算(包括三目运算)则会被自动拆箱成基本类型,所以要小心NPE! ```Java Integer i = 10;//自动装箱,反编译后为Integer integer=Integer.valueOf(1); int b = i;//自动拆箱,反编译后为int i=integer.intValue(); Integer i = new Interger(10); Integer i = 10;//替代上面 ``` 还有一个就是自动拆箱与缓存的问题,Integer如果在[-127,128]间,则 `Integer a = 3`==`Integer b = 3`(在Java6中可以通过 `java.lang.Integer.IntegerCache.high`设置最大值)。所以在这个范围之外就要用equals来比较了。 还有一点是for循环中如果存在大量拆装箱的操作都会造成很多不必要的资源浪费。 具体样例可以看《Java就业面试大全》第14题。 从这里还可以引申出,Byte、Short、Long、Character都有其对应的XxxCache缓存对象。前三者的缓存范围也是 `[-128, -127]`。而Character范围是 `[0, 127]`。并且除了上面的Integer外,这四个范围都不能改变。 #### 如何正确定义接口的返回值 (boolean/Boolean) 类型及命名 (success/isSuccess or deleted/isDeleted) 困扰好久的点终于在这里有了说明,那就是经常遇到的逻辑删除数据库字段 `is_delete`。阿里规约说不能使用 `isDelete`吧啦吧啦一大堆只说了可能导致序列化问题,也没说明该定义成什么规范。 答案是: **`is_success`用 `success`、`is_deleted`用 `deleted`** 。 Lombok的@Data用多了发现entity中有一个细节: 如果属性是boolean类型的话,它的getter方法 `getXxx()`会变成 `isXxx()`。并且如果该属性名是 `is`开头的话只会保留一个 `is`,也就是说 `isDeleted`的getter方法还是跟 `deleted`的getter一样,都是 `isDeleted()`,并且 `isDelete`的set方法会变成 `setDelete`! 这就可能导致序列化的时候出错了。 以下是fastJson、jackson、Gson三种序列化的结果: ```Java class Model3 implements Serializable { private static final long serialVersionUID = 1836697963736227954L; private boolean isSuccess; public boolean isSuccess() { return isSuccess; } public void setSuccess(boolean success) { isSuccess = success; } public String getHollis(){ return "hollischuang"; } } //result Serializable Result With fastjson :{"hollis":"hollischuang","success":true} Serializable Result With Gson :{"isSuccess":true} Serializable Result With jackson :{"success":true,"hollis":"hollischuang"} ``` 从以上可以得出一个结论,就是fastjson和jackson把对象序列化成json时,是通过反射遍历所有getter方法,再根据JavaBeans规则。把isSuccess序列化成success。而Gson则是通过反射遍历类中的所有属性,并把他们序列化成isSuccess。 所以,**前方高能:** 我们把 `isSuccess`用fastjson/jackson进行序列化,再用Gson反序列化,将会得到 `isSuccess=false` `false`?! 因为序列化的时候根据JavaBeans规范解析成了success,而反序列化时是通过反射找success属性,但是Model中的是isSuccess所以找不到返回默认值false! 阿里规约中的这条定义也是从上游卡住了问题的发生,比起下游去处理那些复杂的逻辑更干净省事。 所以直接定义成 `success/deleted`然后可以用MP的 `@TableField`或者 `resultMap`处理映射。 最后就是用Boolean还是boolean的问题了,这里还是有一些争议的。 Boolean的默认值是null,可能出现NPE问题。 boolean的默认值是false,若有问题可能无法感知到异常。 最终还是统一用《java开发手册》《骂出高效》中声明的,尽量用包装类型Boolean,但是要注意避免NULL值(抛出时最好标明是什么原因抛的NPE) ### 5、异常处理 文中把java异常分为两大类:**非受检异常**(unchecked exception)和**受检异常**(checked exception)。 但是我更偏向于用**运行时异常**(runtime exception)和**一般异常**(checked exception)来形容。 具体可以看看《Java就业面试大全》的第34-38题 **异常处理方式**一般有两种: 1、自己处理 2、向上抛,给调用者处理 《手册》中也有明确规定说千万不能只捕获而不处理,或者只是简单的e.printStacktrace。能处理就处理,不能处理就往上抛让调用者头疼。 #### `try-with-resources` Java中的IO流、数据库连接的开销都是非常大的,一直打开状态可能会造成内存泄露问题,所以一般要在finally块中调用close()去施放。 ```Java public void testException(){ BufferedReader br = null; try{ FileReader fileReader = new FileReader("唐宋.txt");//定义文件 br = new BufferedReader(fileReader);//读取文本 while (br.readLine() != null) { System.out.println(br.readLine());//读取一行内容 } } catch (Exception e) { e.printStackTrace(); }finally { try{ if (br != null) { br.close();// 无论如何文件句柄在使用结束后得手动关闭! } }catch (IOException e){ e.printStackTrace(); } } } ``` 可以用Lombok中的 `@Cleanup`+`@SneakyThrows`联动: ```Java @SneakyThrows public void testException(){ @Cleanup BufferedReader br = null; FileReader fileReader = new FileReader("唐宋.txt");//定义文件 br = new BufferedReader(fileReader);//读取文本 while (br.readLine() != null) { System.out.println(br.readLine());//读取一行内容 } } ``` 但是这个方法在业务中还是比较少见的,用起来可能会比较怂。还是推荐下面阿里推荐的方式: ```Java public void testException(){ try (BufferedReader br = new BufferedReader(new FileReader("唐宋.txt"))) { while (br.readLine() != null) { System.out.println(br.readLine());//读取一行内容 } } catch (Exception e) { e.printStackTrace(); } } ``` 虽然把获取文件的方法都压缩到了try()中,但确实很短好吧,同时还能决定出错时要抛什么异常,更加实用。 还有一点就是**finally和return的执行顺序**,这点在这里有详细说明: [《java就业面试大全》第31题](http://www.tangsong.fun/index.php/JavaTest1.html) ### 6、集合类 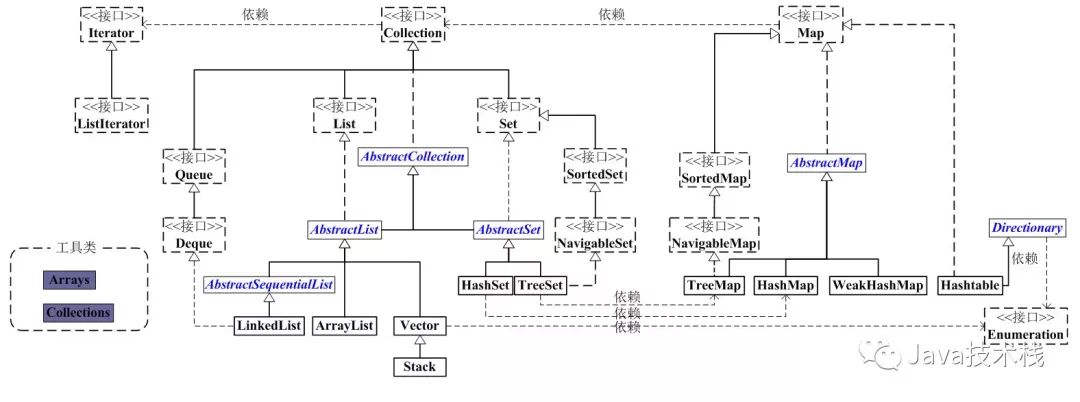 集合类,简直是面试官的最爱,(在《java...大全》)重复出现的问题这里不再进行讲解: **(1)Collection 和 s Collections 区别**:第57题 **(2)Set和List区别** **(3)ArrayList和LinkedList和Vector的区别**:49、50 **(4)HashMap、HashTable、ConcurrentHashMap区别**:51 #### ArrayList 使用了 transient 关键字进行存储优化,而 Vector 没有,为什么? 这里先说明一下 `transient`关键字: `transient`一般是在序列化中使用。如果一个用户有一些敏感信息(如密码,银行卡号等),为了安全起见,不希望在网络操作(主要涉及到序列化操作,本地序列化缓存也适用)中被传输,这些信息对应的变量就可以加上transient关键字。换句话说,这个字段的生命周期仅存于调用者的内存中而不会写到磁盘里持久化。 **总之,java 的transient关键字为我们提供了便利,你只需要实现Serilizable接口,将不需要序列化的属性前添加关键字transient,序列化对象的时候,这个属性就不会序列化到指定的目的地中。** 在使用中主要注意以下几点: * 1)一旦变量被transient修饰,变量将不再是对象持久化的一部分,该变量内容在序列化后无法获得访问。 * 2)transient关键字只能修饰变量,而不能修饰方法和类。注意,本地变量是不能被transient关键字修饰的。变量如果是用户自定义类变量,则该类需要实现Serializable接口。 * 3)被transient关键字修饰的变量不再能被序列化,一个Static静态变量不管是否被transient修饰,均不能被序列化。(反序列化中读取到的值也只是当前JVM中对应static变量的值,而不是通过反序列化得出的) * 4)若序列化操作是通过Externalizable接口,则没有任何东西可以自动序列化,需要在writeExternal方法中进行手工指定所要序列化的变量,这与是否被transient修饰无关。 ```java /** * 将ArrayList的实例状态保存到流中。即,对其实现序列化 * * @serialData 根据数据实例的长度(int),以适当的顺序写入到Object对象中 */ private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException{ // 写出元素计数,以及任何隐藏内容 // modCount list被结构(列表大小)修改的次数 int expectedModCount = modCount; // writeObject默认调用的序列化方法,将当前类的非静态和非瞬态字段写入此流 s.defaultWriteObject(); // 写出clone()方法的大小,size即ArrayList中具体存放元素的个数 // 而elementData.length则是ArrayList内部自动扩容数组的长度 s.writeInt(size); // 按照正确的顺序写出所有元素 for (int i=0; i<size; i++) { // 将指定的对象写入ObjectOutputStream // elementData 存储ArrayList的元素的数组缓冲区,大小等于ArrayList的length。 s.writeObject(elementData[i]); } if (modCount != expectedModCount) { throw new ConcurrentModificationException(); } } ``` ArrayList 实现了 writeObject 方法,从 `s.writeInt(size)`可以看到只保存了非 null 的数组位置上的数据。即 list 的 size 个数的 elementData。 需要额外注意的一点是,ArrayList 的实现,提供了 `fast-fai`机制,可以提供弱一致性。 ```java /** * 将Vector的实例状态保存到流中。即,对其实现序列化 * 此方法执行同步以确保序列化数据的一致性 */ private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException { final java.io.ObjectOutputStream.PutField fields = s.putFields(); final Object[] data; synchronized (this) { // capacityIncrement 容量的大小,当小于写入的容量时自动加倍扩容 fields.put("capacityIncrement", capacityIncrement); // elementCount 数组缓存区的大小 fields.put("elementCount", elementCount); // Vector的elementData中最后一个元素之后的所有数组元素均为null // 所以直接clone()的话后面的null也会被转移进去 data = elementData.clone(); } fields.put("elementData", data); s.writeFields(); } ``` Vector 也实现了 writeObject 方法,但方法并没有像 ArrayList 一样进行优化存储,`data = elementData.clone()`时会把 null 值也拷贝。 通过对比不难得出: **保存相同内容的 Vector 与 ArrayList,Vector 的占用的字节比 ArrayList 要多。** **总结:** * ArrayList 是非同步实现的一个单线程下较为高效的数据结构(相比 Vector 来说)。ArrayList 只通过一个修改记录字段提供弱一致性,主要用在迭代器里。没有同步方法。即上面提到的 Fast-fail 机制.ArrayList 的存储结构定义为 transient,重写 writeObject来实现自定义的序列化,优化了存储。 * Vector 是多线程环境下更为可靠的数据结构,所有方法都实现了同步。 #### 那么, `SynchronizedList`和 `Vector`的差别有是什么呢? 两者的数据增长区别跟ArrayList和Vector的区别是一样的,更多是同步代码块(`SynchronizedList`)和同步方法(`Vector`)的区别,这使得SynchronizedList 有很好的扩展和兼容功能。他可以将所有的 List 的子类转成线程安全的类。 SynchronizedList 中实现的类并没有都使用 synchronized同步代码块。其中有 listIterator 和 listIterator(int index)并没有做同步处理。但是Vector 却对该方法加了方法锁。 所以说,在使用 SynchronizedList 进行遍历的时候要手动加锁。 另外,SynchronizedList 可以指定锁定的对象,没有指定的话默认跟Vector一样锁定this对象。(静态代码块可以选择对哪个对象加锁,但是静态方法只能给 this 对象加锁) #### Set 如何保证元素不重复? 在之前58题的时候有稍微提到过一部分,这里再详细说明一下 Set体系中主要分为 `HashSet`、`TreeSet`。 (1)**`TreeSet`:**通过二叉树实现的,其中的数据是自动排好序的,不允许放入null值。 它的底层是TreeMap的keySet(),是按照key排序的。而 TreeMap 是基于红黑树实现的,红黑树是一种平衡二叉查找树,它能保证任何一个节点的左右子树的高度差不会超过较矮的那棵的一倍。所以TreeSet也是CompareTo()来判断元素重复的。 (2)**`HashSet`:**底层基本都是通过HashMap实现的,它的底层就是用HashMap存储数据。 当向 HashSet 中添加元素的时候,首先计算元素的 hashcode值,然后通过扰动计算和按位与的方式计算出这个元素的存储位置,如果这个位置位空,就将元素添加进去;如果不为空,则用 equals 方法比较元素是否相等,相等就不添加,否则找一个空位添加。 这点在51题有提及到。 Last modification:August 15, 2022 © Allow specification reprint Like 0 喵ฅฅ
2 comments
LinkedHashSet
LinkedHashSet继承自HashSet,并且其内部是通过LinkedHashMap来实现的,而LinkedHashMap又继承自HashMap,更多的是属于Map范畴了,这块在之前的51题中也有讲到了。