Loading... ## 大型数据库设计原则 ### 高并发原则 #### 高并发场景的解决方案 * **垂直扩展**:通过软件技术或者升级硬件,来提高单机的性能。 * **水平扩展**:通过增加服务器的节点个数,来横向扩充系统的性能。 常用:集群(失败迁移、负载均衡)、分布式 ### CAP原则 * **一致性C** 在同一时刻,所有节点中的数据都是相同的。 * **可用性A** 在合理的时间范围内,系统能够提供正常的服务。 * **分区容错性P** 当分布式系统中的一个或多个节点发生网络故障(网络分区),从而脱离整个系统的网络环境时,系统仍然能够提供可靠的服务。 **CAP中无法三者同时满足** ### ACID原则 * **原子性(Atomicity)** 指事务是一个不可再分割的工作单元,事务中的操作要么都发生,要么都不发生。跟CAP的C其实差不多意思。 * **一致性(Consistency)** 指事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。<br>(通俗的说:我和你的钱加起来一共是2000,那么不管我和你之间如何转账,转几次账,事务结束后我们的钱相加起来应该还得是2000,这就是事务的一致性。 ) * **隔离性(Isolation)** 多个用户并发访问操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。<br>四种隔离级别:`READ_UNCOMMITTED`、`READ_COMMITTED`、`REPEATABLE_READ`、`SERIALIZABLE` * **持久性(Durability)** 指事务所对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。(断电或者单台服务器炸了数据还是存在) ### BASE分布式思想原则 * **基本可用(Basically Available)** 是指一个分布式系统的一部分发生问题变得不可用时,其他部分仍然可以正常使用,也就是允许分区失败的情形出现。 * **软状态(Soft-state)** 是指状态可以有一段时间不同步,具有一定的滞后性。 * **最终一致性(Eventual consistency)** 允许后续的访问操作可以暂时读不到更新后的数据,但是经过一段时间之后,必须最终读到更新后的数据。 ### 幂等性原则 幂等性原则是对调用服务次数的一种限制,即无论对某个服务提供的接口调用多次还是一次,其结果都是相同的。(一瞬间狂点抽奖按钮,只执行一次) #### 实现方式 * 算法 * 去重表:每次操作(点抽奖按钮)会生成一个uuid,在**去重表**中查询执行的uuid是否存在,如果存在直接返回结果,如果不存在则去执行核心操作(抽奖)并且将uuid写入**去重表**,最后再返回结果。 #### 场景保证 * 插入数据或者更新数据的时候,更新主要因为并发原因要保证 * 处理事项的时候,例如从mq取数据的脚本同时处理多个事情 #### 如何保证 (1)如果场景为soa调用的时候,这时候例如我们要插入一些数据,如果在网络波动的情况下,soa返回可能是失败的,但是调用其实已经被处理了,这时候soa的重试机制就会导致异常。 **处理方式:** 例如一般情况下的获取soa的方法:`SoaClient::getSoa('system', 'service')`如果说我们要确保幂等性的场景,这时候可以写为 `SoaClient::getSoa('system', 'service', 1)` (2)如果场景为处理mq的脚本,这时候会发生以下的情形:获取到mq数据后,处理发生了异常,这时候没有删除mq的值导致mq的值再次被处理,也就是所谓的重试;也可能出现获取到mq后,我们可能要处理三四件事情,这时候第一件事情处理完了,第二件处理时失败,这时候重试也会导致第一件事情重复发生。 **处理方式:** 增加msg_id处理过的记录,以便防止重复执行,具体参考以下代码: ```php /** * 处理新人赠送红包 */ public function start() { $mqEmpty = false; $redis = r("avoid_repeat_redis"); LOG::i('注册送余额【start】'); while (!$mqEmpty) { //从mq获取相关注册队列 $soa = SoaClient::getSoa('tqmq_v2', 'operation'); $result = $soa->pop(self::MQ_QUEUE); //如果发生异常 if ($soa->hasError()) { LOG::e("MQ调用发生异常! code:" . $soa->getErrorCode() . ",msg:" . $soa->getErrorMsg()); exit; } //有内容的时候则进行处理 if ($result['msg_id']) { //判断消息是否已经被处理过了 $key = "red_activity_handle_first_" . $result['msg_id']; $isExist = $redis->get($key); if($isExist){ break; } $content = json_decode($result['msg_body'], true); $service = s('redActivity'); $service->send($content['uid'], $content['token']); if ($service->hasError()) { LOG::w("处理注册送红包时发生了异常:" . var_export($content, true) . ' ' . $service->getErrorMsg()); break; } $redis->set($key, time()); $redis->expire($key, 24 * 60 * 60); $soa->remove(self::MQ_QUEUE, $result['msg_id']); } else { $mqEmpty = true; } } LOG::i('注册送余额【end】'); } ``` ### 原子性原则 这点其实在ACID中已经涉及到了。因为在公司的案例中有体现到特意拿出来再说明一次: 在这边所说的原子性,主要方面是不管从哪里来的请求,我们能够保证仅处理一次,而不会处理多次。 #### 出错场景 * 匿名注册设备毫秒级多次注册导致的唯一键重复 * 直播的升级提醒因为订单并行原因可能出现多次 #### 解决方案 一般处理方式分为锁和原子利用。 锁的话,一般不建议采用,因为容易造成系统的性能问题,现在仅推荐在一些特殊场景下以及go语言并发场景中使用。 原子利用也就是利用系统中的原子性保障来实现原子操作,例如我们常见的redis的各种原子操作。 例如拿匿名注册来说,在首次注册的时候,我们可以通过incr一个数值,例如【distinctregister用户id】,并且设置一个15秒过期时间,在redis中,incr会返回当前值为多少,可以看下文档,它是一个原子性的操作。 因此我们可以设置为只有当incr为1的时候才进行操作,这时候我们可以保证仅有一个线程会去执行插入数据库的操作,以防止同时两个插入操作导致的唯一键重复的问题。 (其实同样也是跟处理幂等性是一样的问题) ### 数据共享原则 #### (1)Session Replication 在客户端第一次发出请求后,处理该请求的服务端就会创建一个与之对应的Session对象,用于保存客户端的状态信息,之后为了让其他服务端也能保存一份此Session对象,就需要将此Session对象在各个服务端节点之间进行同步。 **缺点:** (1)容易引起广播风暴(服务器太多,Tomcat假设能处理300个链接,但是200个服务器都在处理共享,导致Tomcat实际上只能处理100个链接) (2)会造成严重的冗余(服务器太多,一个session存放到200个服务器,但它其实只需要用到一两个) #### (2)Session Sticky Session Sticky是通过Nginx等负载均衡工具对各个用户进行标记(例如对Cookie标记),使每个用户在经过负载均衡工具后都请求固定的服务器节点。(经nginx编辑后,凡是X类型的请求都走A服务器,凡是Y类型的请求都走B服务器,有点类似读写分离) **缺点:** 不支持高可用(如果A坏了X类型的Session只有A服务器一份) #### (3)独立Session服务器(推荐) 将系统中所有的Session对象都存放到一个独立的Session服务中,之后各个应用服务再分别从这个Session服务中获取需要的Session对象。(把所有Session对象都放到Redis中,每次先去Redis看下是否存在再执行操作。利于横向扩展。) ### 无状态原则 无状态 即 **无数据** 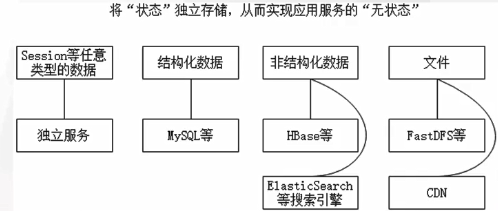 跟数据共享原则中的**独立Session服务器**是一样的。在“无状态”的服务器中,单个服务的宕机、重启等都不会影响到集群中的其他服务,并且容易对应用服务器进行横向扩展。 另一方面,将带有数据的服务设置为“有状态”,并进行集群的“集中部署”(如Mysql集群),可以降低集群内部数据同步带来的延迟。 当然还有一些诸如ACID之类的原则待补充 --- ## 分布式微服务架构解读 分布式微服务架构的出现是为了满足**高吞吐**、**高并发**、**低延迟**、**负载均衡** ### 一、海量承载 #### (1)高吞吐 实现高吞吐一方面是要进行**程序优化**,如**页面的静态化、动静分离**。以及上文所说的解决用户跟踪问题的**Session共享**或**Header请求头中的Token**(Token被越来越多采用,同样也是用Redis存);另一方面是要实现集群的分层调用: ##### 集群分层调用 负载均衡一般有以下几种实现方式: * **HTTP重定向负载均衡**:实际上每个请求都需要发送两次(重定向),效率太低了 * **DNS域名解析负载均衡**:通过DNS服务器解析成不同的IP地址,缺点是不能完全操控DNS服务器因为它基本都是属于运营商的。 * **反向代理负载均衡(荐)**:Nginx,有瓶颈(可以做集群) * **IP负载均衡**:跟反代原理差不多,只不过它依赖于网关服务器 * **数据链路层负载均衡(荐)**:亿级。Web服务器集群的IP地址相同,只是Max地址不同。请求时访问负载均衡服务器会自动修改成要访问的Mac地址。而且响应的数据直接返回给请求IP,不用通过负载均衡服务器转发。 负载均衡一般通过以下几种算法实现: 轮询、**加权轮询**、随机、**最少连接**、源地址散列 #### (2)低延迟 低延迟主要包括了**异步处理**、**数据库优化(数据库集群、读写分离、分库分表)**、**缓存**、**NOSQL数据库(重)** ### 二、服务器管理 * **可扩展性** 包括微服务(Zookeeper、Eureka)、消息队列(MQ)、分布式事务系统 * **可维护性** 包括统一日志、自动部署Docker ### 三、开发效率 * 通信问题 使用微服务框架如Dubbo(RPC)、SpringCloud(REST)解决通信问题 * 模块分工 IaaS/Paas/Saas云服务 --- 分布式的出现可以理解为是业务推到了技术,分布式技术只是解决高并发的其中一种方案,当然还有如:**分地域部署、JVM优化、SQL优化、代码细节优化**等等。 Last modification:August 15, 2022 © Allow specification reprint Like 0 喵ฅฅ
2 comments
又看完了