Loading... ## 客户端环境搭载(IDEA) 1.解压Linux上的Hadoop3.2.1到Windows下,用[bin.zip][1]替换掉里面的bin文件夹 可以直接去[winutils](https://github.com/TangSong99/winutils)下找对应版本的bin替换里面文件,一般只需要添加 `winutils.exe`和 `hadoop.dll` 2.配置环境变量 ```path HADOOP_HOME C:\hadoop-3.2.1 --- PATH %HADOOP_HOME%\bin ``` 3.创建Maven项目: 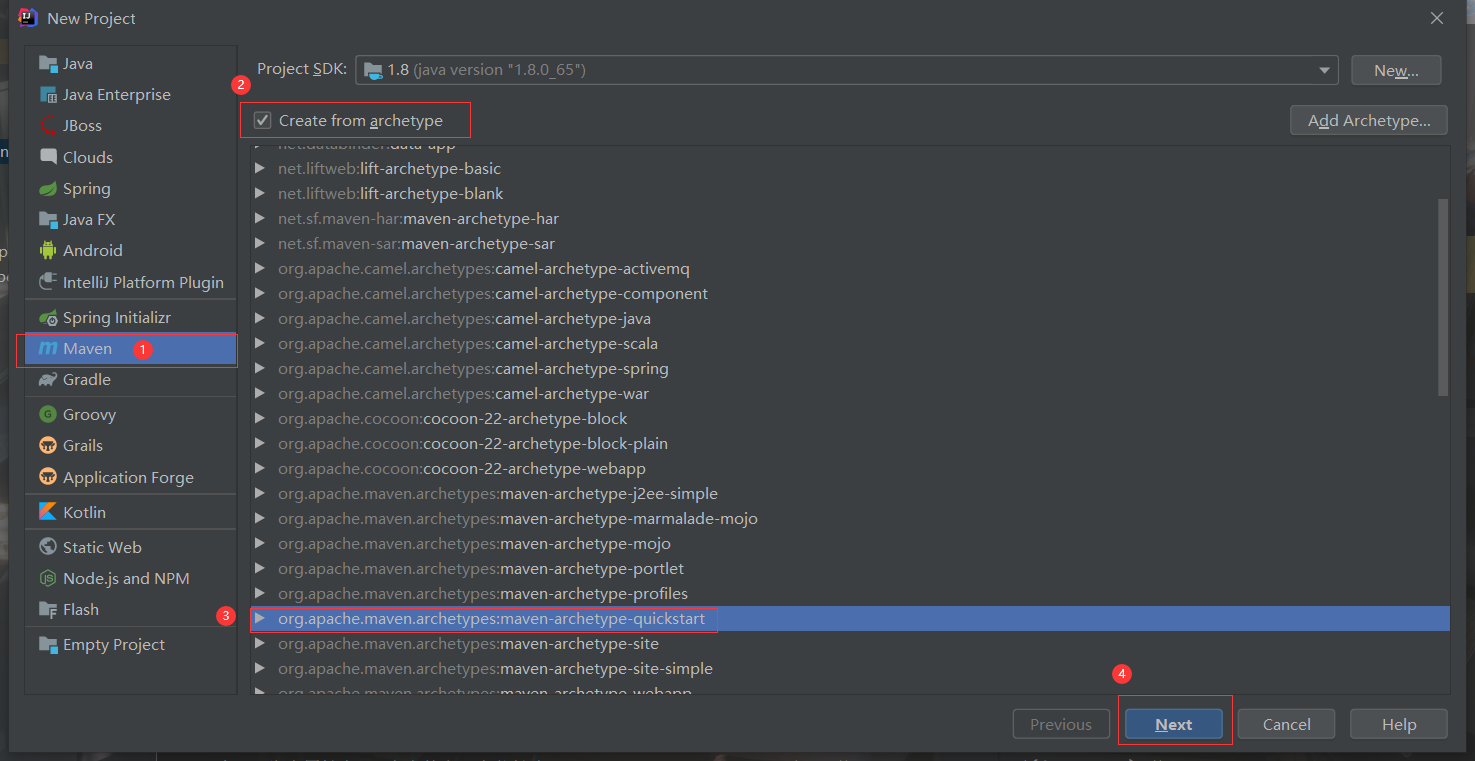 4.配置pom.xml ```XML <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.hadoop</groupId> <artifactId>hdfs01</artifactId> <version>1.0</version> <name>hdfs01</name> <!-- FIXME change it to the project's website --> <url>http://www.htfs01.com</url> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <maven.compiler.source>1.7</maven.compiler.source> <maven.compiler.target>1.7</maven.compiler.target> </properties> <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.11</version> <scope>test</scope> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-core</artifactId> <version>2.8.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>3.2.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.2.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>3.2.1</version> </dependency> <!-- <dependency>--> <!-- <groupId>jdk.tools</groupId>--> <!-- <artifactId>jdk.tools</artifactId>--> <!-- <version>1.8</version>--> <!-- <systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>--> <!-- </dependency>--> </dependencies> <build> <pluginManagement><!-- lock down plugins versions to avoid using Maven defaults (may be moved to parent pom) --> <plugins> <!-- clean lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#clean_Lifecycle --> <plugin> <artifactId>maven-clean-plugin</artifactId> <version>3.1.0</version> </plugin> <!-- default lifecycle, jar packaging: see https://maven.apache.org/ref/current/maven-core/default-bindings.html#Plugin_bindings_for_jar_packaging --> <plugin> <artifactId>maven-resources-plugin</artifactId> <version>3.0.2</version> </plugin> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.8.0</version> </plugin> <plugin> <artifactId>maven-surefire-plugin</artifactId> <version>2.22.1</version> </plugin> <plugin> <artifactId>maven-jar-plugin</artifactId> <version>3.0.2</version> </plugin> <plugin> <artifactId>maven-install-plugin</artifactId> <version>2.5.2</version> </plugin> <plugin> <artifactId>maven-deploy-plugin</artifactId> <version>2.8.2</version> </plugin> <!-- site lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#site_Lifecycle --> <plugin> <artifactId>maven-site-plugin</artifactId> <version>3.7.1</version> </plugin> <plugin> <artifactId>maven-project-info-reports-plugin</artifactId> <version>3.0.0</version> </plugin> </plugins> </pluginManagement> </build> </project> ``` 5.配置log4j.properties ```properties hadoop.root.logger=DEBUG, console log4j.rootLogger = DEBUG, console log4j.appender.console=org.apache.log4j.ConsoleAppender log4j.appender.console.target=System.out log4j.appender.console.layout=org.apache.log4j.PatternLayout log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{2}: %m%n ``` 如果还出现WARN则在main函数下添加 `BasicConfigurator.configure(); `//自动快速地使用缺省Log4j环境。 --- ## NameNode故障处理 ### 方法一:将SecondaryNameNode中数据拷贝到NameNode存储数据的目录; 1.kill -9 NameNode进程 2.删除NameNode存储的数据(`/usr/hadoop/centos01/dfs/name`) `rm -rf /usr/hadoop/centos01/dfs/name/*` 3.拷贝SecondaryNameNode(本集群还是存在master中)中数据到原NameNode存储数据目录 `cd /usr/hadoop/centos01/dfs` `scp -r root@centos02:/usr/local/hadoop/temp/dfs/namesecondary ./name/`(2NN不在本机上) 4.重新启动NameNode `/usr/local/hadoop/sbin/hadoop-daemon.sh start namenode` ### 方法二:使用-importCheckpoint选项启动NameNode守护进程,从而将SecondaryNameNode中数据拷贝到NameNode目录中。(标准) 1.修改hdfs-site.xml中的检查点 ```XML <property> <name>dfs.namenode.checkpoint.period</name> <value>120</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/usr/hadoop/centos01/dfs/data/name</value> </property> ``` 2.kill -9 NameNode进程 3.删除NameNode存储的数据(`/usr/hadoop/centos01/dfs/name`) `rm -rf /usr/hadoop/centos01/dfs/name/*` 4.如果SecondaryNameNode不和NameNode在一个主机节点上,需要将SecondaryNameNode存储数据的目录拷贝到NameNode存储数据的平级目录,并删除in_use.lock文件 `scp -r root@centos02:/usr/local/hadoop/temp/dfs/namesecondary ./` `rm -rf namesecondary/in_use.lock` 5.导入检查点数据(等待一会ctrl+c结束掉) `bin/hdfs namenode -importCheckpoint` 6.启动NameNode `sbin/hadoop-daemon.sh start namenode` --- ## 安全模式  (1)bin/hdfs dfsadmin -safemode get (功能描述:查看安全模式状态) (2)bin/hdfs dfsadmin -safemode enter (功能描述:进入安全模式状态) (3)bin/hdfs dfsadmin -safemode leave (功能描述:离开安全模式状态) (4)bin/hdfs dfsadmin -safemode wait (功能描述:等待安全模式状态) ### 模拟等待安全模式操作 (1)查看当前模式 `hdfs dfsadmin -safemode get` Safe mode is OFF (2)先进入安全模式 `bin/hdfs dfsadmin -safemode enter` (3)创建并执行下面的脚本 在hadoop路径上,编辑一个脚本safemode.sh `touch safemode.sh` `vim safemode.sh` ```sh #!/bin/bash hdfs dfsadmin -safemode wait hdfs dfs -put /opt/module/hadoop-2.7.2/README.txt / ``` `chmod 777 safemode.sh` `./safemode.sh `(脚本进入等待状态) (4)再打开一个窗口,执行 `bin/hdfs dfsadmin -safemode leave` (5)观察当前窗口:Safe mode is OFF 再观察上一个窗口:有程序执行,HDFS集群上已经有上传的数据了。 --- ## NameNode多目录配置(了解) 1.NameNode的本地目录可以配置成多个,且每个目录存放内容相同,增加了可靠性,但是NameNode挂掉后所有目录也将都挂掉。 2.具体配置如下 (1)在hdfs-site.xml文件中增加如下内容 ```xml <property> <name>dfs.namenode.name.dir</name> <value>file:///${hadoop.tmp.dir}/dfs/name1,file:///${hadoop.tmp.dir}/dfs/name2</value> </property> ``` (2)停止集群,删除data和logs中所有数据。 ```hdfs [atguigu@hadoop102 hadoop-2.7.2]$ rm -rf data/ logs/ [atguigu@hadoop103 hadoop-2.7.2]$ rm -rf data/ logs/ [atguigu@hadoop104 hadoop-2.7.2]$ rm -rf data/ logs/ ``` (3)格式化集群并启动。 ```hdfs [atguigu@hadoop102 hadoop-2.7.2]$ bin/hdfs namenode –format [atguigu@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh ``` (4)查看结果 ```hdfs [atguigu@hadoop102 dfs]$ ll 总用量 12 drwx------. 3 atguigu atguigu 4096 12月 11 08:03 data drwxrwxr-x. 3 atguigu atguigu 4096 12月 11 08:03 name1 drwxrwxr-x. 3 atguigu atguigu 4096 12月 11 08:03 name2 ``` --- ## 服役新节点 配置:参考前两篇文章(克隆-修改IP、主机名——配置/etc/profile) 启动:直接启动NameNode即可关联到集群 `sbin/hadoop-daemon.sh start datanode` `sbin/yarn-daemon.sh start nodemanager` 负载均衡(非必须):`./start-balancer.sh` --- ## 退役旧节点 ### 一、添加白名单 添加到白名单的主机节点,都允许访问NameNode,不在白名单的主机节点,都会被退出。(但是Utilities下仍会保留该节点的数据存放记录,即在文件的三个存放节点中,若有一个节点不在白名单中则该节点无法启动,但仍会占用三个存放节点之一) (1)在 `/usr/local/hadoop/etc/hadoop`目录下创建 `dfs.hosts`文件(已新克隆centos04节点做演示) `touch dfs.hosts` `vi dfs.hosts` ```hosts centos01 centos02 centos03 ``` (2)在主节点的NameNode的hdfs-site.xml配置文件中增加dfs.hosts属性 ```XML <property> <name>dfs.hosts</name> <value>/usr/local/hadoop/etc/hadoop/dfs.hosts</value> </property> ``` (3)配置文件分发 `xsync hdfs-site.xml` (4)刷新NameNode `hdfs dfsadmin -refreshNodes` (5)更新ResourceManager节点 `yarn rmadmin -refreshNodes` (6)web端查看(centos04从datanode下架) `centos01:50070/dfshelth.html#tab-datanode` (7)负载均衡(非必须) `./start-balancer.sh` ### 二、黑名单退役(标准) 在黑名单上面的主机都会被强制退出。并在退出之前会把节点下的所有资源拷贝到其他负载较小的节点(Utilities下仍会保留该节点的数据存放记录,但是文件存放节点会变成四个其中一个新增一个失效) (1)在 `/usr/local/hadoop/etc/hadoop`目录下创建 `dfs.hosts.exclude`文件(已新克隆centos04节点做演示) `touch dfs.hosts.exclude` `vi dfs.hosts.exclude` ```exclude centos04 ``` (2)在主节点的NameNode的hdfs-site.xml配置文件中增加dfs.hosts.exclude属性 ```XML <property> <name>dfs.hosts.exclude</name> <value>/usr/local/hadoop/etc/hadoop/dfs.hosts.exclude</value> </property> ``` (3)配置文件分发 `xsync hdfs-site.xml` (4)刷新NameNode `hdfs dfsadmin -refreshNodes` (5)更新ResourceManager节点 `yarn rmadmin -refreshNodes` (6)web端查看(centos04仍存在,但已退役) `centos01:50070/dfshelth.html#tab-datanode` 退役节点的状态为 `decommission in progress`(退役中),说明数据节点正在复制块到其他节点 等待退役节点状态为 `decommissioned`(所有块已经复制完成),停止该节点及节点资源管理器。 **`注意`:如果副本数是3,服役的节点小于等于3,是不能退役成功的,需要修改副本数后才能退役** (7)单节点(centos04)退出(重新启动集群后centos04从web端的datanode中下架) `sbin/hadoop-daemon.sh stop datanode` `sbin/yarn-daemon.sh stop nodemanager` (8)负载均衡(非必须): `sbin/start-balancer.sh` --- ## DataNode多目录配置 1.DataNode也可以配置成多个目录,每个目录存储的数据不一样。即:数据不是副本 2.具体配置如下 (1)在hdfs-site.xml文件中增加如下内容 ```XML <property> <name>dfs.datanode.data.dir</name> <value>file:///${hadoop.tmp.dir}/dfs/data1,file:///${hadoop.tmp.dir}/dfs/data2</value> </property> ``` 其余同上:NameNode多目录配置 --- ## Hadoop特性 ### 一、集群间数据拷贝 1.scp实现两个远程主机之间的文件复制 ```hadoop scp -r hello.txt root@hadoop103:/user/atguigu/hello.txt// 推 push scp -r root@hadoop103:/user/atguigu/hello.txt hello.txt// 拉 pull scp -r root@hadoop103:/user/atguigu/hello.txt root@hadoop104:/user/atguigu//是通过本地主机中转实现两个远程主机的文件复制;如果在两个远程主机之间ssh没有配置的情况下可以使用该方式。 ``` 2.采用distcp命令实现两个Hadoop集群之间的递归数据复制 ```hadoop [atguigu@hadoop102 hadoop-2.7.2]$ bin/hadoop distcp hdfs://haoop102:9000/user/atguigu/hello.txt hdfs://hadoop103:9000/user/atguigu/hello.txt ``` ### 二、小文件存档(重)  1.启动集群 `sbin/start-dfs.sh` `sbin/start-yarn.sh` 2.创建目录,往input添加文件 `hadoop fs mkdir -p /user/root/input` 3.把 `/user/root/input`目录里面的所有文件归档成一个叫 `input.har`的归档文件,并把归档后文件存储到 `/user/root/output`路径下。 `bin/hadoop archive -archiveName input.har –p /user/root/input /user/root/output` 4.查看归档文件 `hadoop fs -lsr /user/root/output/input.har`(无法查看到源文件) `hadoop fs -lsr har:///user/root/output/input.har`(通过har可查看到源文件) 5.解归档文件 `hadoop fs -cp har:/// user/root/output/input.har/* /user/root` ### 三、回收站  1.启用回收站,修改core-site.xml,配置垃圾回收时间为1分钟,并修改访问垃圾回收站用户名称默认是dr.who,修改为root用户 ```XML <property> <name>fs.trash.interval</name> <value>1</value> </property> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> ``` 2.配置文件分发 `xsync core-site.xml` 3.查看回收站: 回收站在集群中的路径:`/user/root/.Trash/Current` 4.通过程序删除的文件不会经过回收站,需要调用moveToTrash()才进入回收站 ```Java Trash trash = New Trash(conf); trash.moveToTrash(path); ``` 5.恢复回收站数据 `hadoop fs -mv /user/root/.Trash/Current /user/atguigu/input` 6.清空回收站(以时间戳的形式打包回收站下所有文件,存放时间到后自动删除) `hadoop fs -expunge` ### 四、快照(了解)  (1)开启/禁用指定目录的快照功能 `hdfs dfsadmin -allowSnapshot /user/root/input` `hdfs dfsadmin -disallowSnapshot /user/root/input` (2)对目录创建快照 `hdfs dfs -createSnapshot /user/root/input` 通过web访问 `hdfs://centos01:50070/user/root/input/.snapshot/s…`(快照和源文件使用相同数据) `hdfs dfs -lsr /user/root/input/.snapshot/` (3)指定名称创建快照 `hdfs dfs -createSnapshot /user/root/input miao170508` (4)重命名快照 `hdfs dfs -renameSnapshot /user/root/input/ miao170508 root170508` (5)列出当前用户所有可快照目录 `hdfs lsSnapshottableDir` **(6)比较两个快照目录的不同之处** `hdfs snapshotDiff /user/root/input/ . .snapshot/atguigu170508` (7)恢复快照 `hdfs dfs -cp /user/atguigu/input/.snapshot/s20170708-134303.027 /user` [1]: http://www.tangsong.fun/usr/uploads/2020/03/2806691285.zip Last modification:August 12, 2022 © Allow specification reprint Like 0 喵ฅฅ
One comment
妹妹真棒