Loading... 4399公司2021Java开发工程师(卷一) 总体来说难度不大,偏向基础。但是由于基本没有准备,SpringBoot和文件编程不尽人意。 <!--more--> > **1.在SELECT 语句中使用MAX(列名)时,列名应该(`不限制数据类型`)** Max函数中类型可以是数值类、日期类、字符串类等。字符串比较的是字母的ASCII码 > **2.下面有关servlet service描述错误的是(`B`)?** > A.不管是post还是get方法提交过来的连接,都会在service中处理 > B.doGet/doPost 则是在 javax.servlet.GenericServlet 中实现的 > C.service()是在javax.servlet.Servlet接口中定义的 > D.service判断请求类型,决定是调用doGet还是doPost方法 在 HttpServlet 中已存在 service()方法.缺省的服务功能是调用与 HTTP 请求的方法相应的 do 功能。例如,如果 HTTP 请求方法为 GET,则缺省情况下就调用 doGet()。但如果你重载了该方法,默认操作被覆盖,不再进行转发操作! service()是在javax.servlet.Servlet接口中定义的, 在 javax.servlet.GenericServlet中实现了这个接口, 而 doGet/doPost 则是在 javax.servlet.http.HttpServlet 中实现的,javax.servlet.http.HttpServlet 是javax.servlet.GenericServlet 的子类. init()方法是servlet生命的起点。一旦加载了某个servlet,服务器将立即调用它的init()方法。 service()方法处理客户机发出的所有请求。 destroy()方法标志servlet生命周期的结束。 servlet在多线程下其本身并不是线程安全的。如果在类中定义成员变量,而在service中根据不同的线程对该成员变量进行更改,那么在并发的时候就会引起错误。最好是在方法中,定义局部变量,而不是类变量或者对象的成员变量。由于方法中的局部变量是在栈中,彼此各自都拥有独立的运行空间而不会互相干扰,因此才做到线程安全。 > **3.关系型数据库创建表都有主键。以下对主键描述正确的是(`C`):** > A.主键是唯一索引,唯一索引也是主键 > B.主键是一种特殊的唯一性索引,只可以是聚集索引 > C.主键是唯一、不为空值的列 > D.对于聚集索引来说,创建主键时,不会自动创建主键的聚集索引 主键创建后一定包含一个唯一性索引,唯一性索引并不一定就是主键。 唯一性索引列允许空值,而主键列不允许为空值。主键列在创建时,已经默认为空值 + 唯一索引了。 主键可以被其他表引用为外键,而唯一索引不能。一个表最多只能创建一个主键,但可以创建多个唯一索引。 主键更适合那些不容易更改的唯一标识,如自动递增列、身份证号等。在 RBO 模式下,主键的执行计划优先级要高于唯一索引。 两者可以提高查询的速度。 虽然一般主键默认就是聚集索引,但是并不代表聚集索引的值具有唯一约束,主键不等于具体索引。 > **4.Statement、 PreparedStatement 、CallableStatement 区别和联系** (1)Statement、PreparedStatement和CallableStatement都是接口(interface)。 Statement 场景:普通的不带参的查询SQL PreparedStatement 场景:支持可变参数的SQL CallableStatement 场景:支持调用存储过程,提供了对输出和输入/输出参数(INOUT)的支持; (2)Statement继承自Wrapper、PreparedStatement继承自Statement、CallableStatement继承自PreparedStatement。 (3)静态SQL可以用Statement和PreparedStatement,带参数的用PreparedStatement,存储过程用CallableStatement。但由于PrepareStatement可以防止SQL注入且对于重复执行的语句效率会更高,所以尽量不用Statement。 > **5.CSS选择器优先级:`id选择器>类选择器>标签选择器`** > **6.在MySQL中,关于HASH索引,下列描述不正确的是(`C`)** > A.只用于使用=或者 < = >操作符的等式比较 > B.优化器不能使用HASH索引来加速Order By操作 > C.如果将一个MyISAM表改为HASH索引的MEMORY表,不会影响查询的执行效率 > D.只能使用整个关键字来搜索一行 A.仅仅满足=、in、<=、>=查询,不能范围查询(原先有序的键值经过哈希函数运算,可能不再连续) B.HASH索引无法用于排序操作 C.HASH查找效率高,但重复值多时,查找效率会降低。 D.不能用部分索引建来查询,如 `like` > **7.在一棵二叉树中,度为2的节点有30个,度为1的节点有10个,则叶子节点的个数是(`31`)** N = N2 + N1 + N0 N = 2*N2 + N1 + 1 => N0 = N2 + 1 设非空二叉树结点数为90,其中度为1的结点数为47,度为2的结点数为(`(90-1-47)/2=21`) > **8.下面有关JDK中的包和他们的基本功能,描述错误的是(`C`)** > A.java.awt: 包含构成抽象窗口工具集的多个类,用来构建和管理应用程序的图形用户界面 > B.java.io: 包含提供多种输出输入功能的类 > C.java.lang: 包含执行与网络有关的类,如URL,SCOKET,SEVERSOCKET > D.java.util: 包含一些实用性的类 * **java.lang:该包提供了Java编程的基础类,例如 Object、Math、String、StringBuffer、System、Thread等,不使用该包就很难编写Java代码了。** * java.util:该包提供了包含集合框架、遗留的集合类、事件模型、日期和时间实施、国际化和各种实用工具类(字符串标记生成器、随机数生成器和位数组)。 * java.io:该包通过文件系统、数据流和序列化提供系统的输入与输出。 * **java.net:该包提供实现网络应用与开发的类。** * java.sql:该包提供了使用Java语言访问并处理存储在数据源(通常是一个关系型数据库)中的数据API。 * java.awt:这两个包提供了GUI设计与开发的类。java.awt包提供了创建界面和绘制图形图像的所有类 * javax.swing:包提供了一组“轻量级”的组件,尽量让这些组件在所有平台上的工作方式相同。 * java.text:提供了与自然语言无关的方式来处理文本、日期、数字和消息的类和接口。 > **9.下标从1开始,在含有n个关键字的小根堆(堆顶元素最小)中,关键字最大的记录有可能存储在(`D`)位置上** > A.[n/2] > B.[n/2]-1 > C.1 > D.[n/2]+2 **[]取整为向下取整!** 小根堆的最大记录一定在叶子节点上,故要**大于[n/2]** 更简单的做法是把n=3带入最小堆模型中,即可排除ABC > **10.路由器相关问题:** 路由器在网络中起数据包转发和路径选择作用。通常的路由器可以支持多种网络层协议,并提供不同协议之间的分组转换。 相对于交换机和网桥来说,路由器具有更加复杂的功能 路由器可以实现不同子网之间的通信,交换机和网桥不能 路由器可以实现虚拟局域网之间的通信,交换机和网桥不能 > **11.下面有关JAVA异常类的描述,说法错误的是(`D`)** > A.异常的继承结构:基类为Throwable,Error和Exception继承Throwable,RuntimeException和IOException等继承Exception > B.非RuntimeException一般是外部错误(非Error),其必须被 try{}catch语句块所捕获 > C.Error类体系描述了Java运行系统中的内部错误以及资源耗尽的情形,Error不需要捕捉 > D.RuntimeException体系包括错误的类型转换、数组越界访问和试图访问空指针等等,必须被try{}catch语句块所捕获 运行时异常RuntimeException 体系包括错误的类型转换、数组越界访问和试图访问空指针等等。可以被try/catch包围,但一般不进行处理。 可能抛出系统异常的方法是不需要申明异常的。 编译时异常如果产生,必须处理,要么捕获,要么抛出。 finally只有在try被成功执行后(try中没有 `System.exit(0);`)才会被执行。如果当一个线程在执行 try 语句块或者 catch 语句块时被打断(interrupted)或者被终止(killed),与其相对应的finally 语句块可能不会执行。还有更极端的情况,就是在线程运行 try 语句块或者 catch 语句块时,突然死机或者断电,finally 语句块肯定不会执行了。 > **12.JVM内存不包含如下哪个部分(`D`)** > A.Stacks > B.PC寄存器 > C.Heap > D.Heap Frame 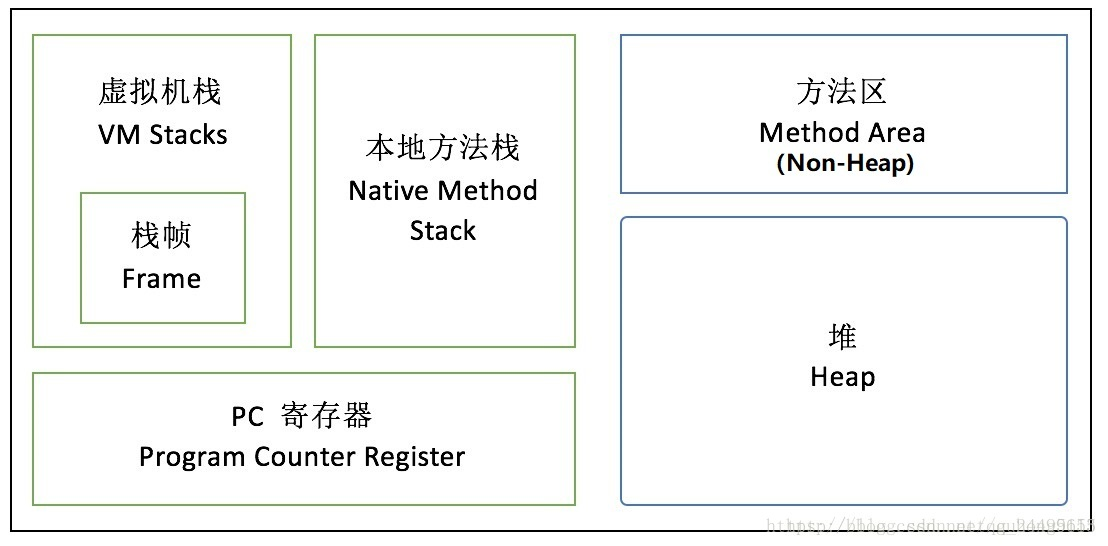 > **13.若磁盘的转速提高一倍,则(`C`)。** > A.平均存取时间减半 > B.平均找道时间减半 > C.平均等待时间减半 > D.存储密度可以提高一倍 磁盘的转速提高一倍只是提高了在选中磁道上的旋转等待时间,而平均存取时间包括两部分,即平均寻道时间加上选中磁道上的旋转等待时间。因此,“平均存取时间减半”的说法是错误的。而平均寻道时间与磁盘的转速没有什么关系。 > **14.类似此题:关于equals()与hashcode()说法不正确的是(`C`)** > A.equals()相等的两个对象,hashcode()一定相等 > B.equals()方法不相等的两个对象,hashcode()有可能相等 > C.hashcode()相等,equals()一定相等 > D.hashcode()不等,equals()一定也不相等 > **15.进程和程序的本质区别在于(`D`)** > A.前者分时使用CPU,或者独占CPU > B.前者存储在内存,后者存储在外存 > C.前者具有异步性,后者具有可再现性 > D.前者可以并发执行,后者不能并发执行 * 进程是动态的,程序是静态的。 程序是有序的代码集合;进程是程序的执行,进程有核心态/用户态。 * 进程是暂时的,程序是永久的。 进程是一个状态变化的过程;程序可长久保存。 * 进程与程序的组成不同。 进程的组成包括程序、数据和进程控制块。 > **16.以下哪个ip不和10.11.12.91/28处于同一个子网(`D`)** > A.10.11.12.85/28 > B.10.11.12.88/28 > C.10.11.12.94/28 > D.10.11.12.97/28 28位网络号,所以只看最后一位的前四位二进制数即可。 91:`0101 1011` 85:`0101 0101` 88:`0101 1000` 94:`0101 1110` 97:`0110 0001` (一般**不是同一子网**的单选只要看最小和最大即可) > **17.一个队列的入列序为 1234 ,则队列的可能输出序列为(`1234`)** FIFO > **18.下面关于进程互斥的论述中哪个是不正确的?(`D`)** > A.信号量是一种进程互斥技术 > B.管程是一种进程互斥技术 > C.消息机制可用于实现进程互斥 > D.消息机制不能支持进程间的互斥 考察操作系统中进程互斥的相关知识。 **相关概念:** **进程互斥:** 两个或两个以上的进程,不能同时进入关于同一组共享变量的临界区域,否则可能发生与时间有关的错误,这种现象被称作进程互斥。也就是说,一个进程正在访问临界资源,另一个要访问该资源的进程必须等待。 **临界资源:** 系统中某些资源一次只允许一个进程使用(也叫临界资源、互斥资源、共享资源)。 **临界区(互斥区):** 各个进程中对某个临界资源(共享变量)试试操作的程序片段。 A选项,信号量实现互斥:采用一元信号量,即:该信号量的计数器,只能为0或1。一个进程要获取临界资源时,先获取对应的信号量资源;当无信号量资源时,则该进程阻塞等待,进入等待队列。当有信号量资源时,则对该信号量资源进行P(-1)操作,然后获取该临界资源。当该进程使用完临界资源时,将释放信号量资源(对信号量资源进行V(+1)操作),然后唤醒等待队列中的进程。因此A选项正确。 B选项,管程实现互斥:是一个资源管理模块,其中包含了共享资源的数据结构,以及由对该共享数据结构实施操作的一组过程(方法)所组成的资源管理程序。把分散在各个进程中互斥地访问公共变量的那些临界区集中起来管理,管程的局部变量只能由该管程的过程存取,进程只能互斥地调用管程中的过程。因此B选项正确。 C选项,在消息缓冲通信中,消息队列属于临界资源,在消息缓冲区操作的前后,都要执行P、V操作,对该队列进行互斥访问控制。因此C选项正确,D选项错误。 综上本题选D。 > **19.有3台复印机,平均每台每周工作50小时,每台每周最少工作40小时,那么一台复印机每周最多会工作多少小时:(`70`)** 50\*3 - 40\*2 = 70 > **20.书架上有编号为1-19的19本书,从中拿5本,问5本编号都不相邻的拿法有多少种?`3003`** 可以这样理解:19本抽出5本后剩下14本。因为这5本不相邻,所以可以相当于是14本书的空位中插入5本 = C(5,15)= 3003 > **一、如何理解Java的平台独立性?** > Java有句非常有名的口号:“一次编写,随处运行”,依靠的就是JVM提供的平台独立性。本质上来讲,就是**通过虚拟机技术,通过限制一些功能,达到屏蔽底层细节的目的。** 更具体得说,Java的平台独立性体现在两个方面:**体系结构无关**、**可移植**。 * 体系结构无关 JVM里设计了一套字节码指令系统,这套指令系统跟特定的体系结构没有关系。精心设计的字节码不仅可以在各个机器上运行,还可以迅速得翻译成本地机器的代码。解释字节码运行肯定比先编译后运行慢得多,因此虚拟机提供了即时编译子系统,用于将使用最频繁的字节码翻译成本地指令,这个策略十分有效。 * 可移植 与C和C++不同,Java规范中没有“依赖具体实现”的地方,基本数据类型的大小以及有关的算法都做了明确的定义。例如:在Java中int永远为32位整数,而在C/C++中,int可能是16位整数、32位整数,也可能是编译器提供商指定的其他大小。<br>作为系统组成部分的类库,定义了可移植的接口。例如:一个抽象的Window类给出了在UNIX、Windows和Mac OS环境不同的实现;文件路径分隔符——File.separator,针对不同的文件系统也有不同的实现。 > **二、Collection和Collections的区别** * Collection是集合类的上级接口,继承与他的接口主要有Set 和List. * Collections是针对集合类的一个工具类/帮助类,他提供一系列静态方法(直接通过类调用)实现对各种集合的搜索、排序、线程安全化等操作,服务于Collection框架。 > **三、Spring Boot 打成的 jar 和普通的 jar 有什么区别 ?** Spring Boot 中默认打包成的 jar 叫做 **可执行jar**,这种 jar 不同于普通的 jar,普通的 jar 不可以通过 `java-jar xxx.jar` 命令执行,主要是被其他应用依赖。而SpringBoot 打成的 jar 可以执行,但是不可以被其他的应用所依赖,即使强制依赖,也无法获取里边的类。 > **四、SpringBoot如何解决跨域问题** [SpringBoot系列(八) 分分钟学会SpringBoot多种跨域解决方式](https://mp.weixin.qq.com/s/eWXAPj7Zr3dDRWL2x-57MA) > **五、XML的特点** xml 是一种可扩展性标记语言,支持自定义标签(使用前必须预定义)使用 DTD 和 XML Schema 标准化 XML 结构。 Xml 常用解析器有 2 种,分别是:DOM 和 SAX;主要区别在于它们解析 xml 文档的方式不同。使用 DOM 解析,xml 文档以 DOM树形结构加载入内存,而 SAX 采用的是事件模型。 **优点:** 用于配置文件,格式统一,符合标准;用于在互不兼容的系统间交互数据,共享数据方便; **缺点:** xml 文件格式复杂,数据传输占流量,服务端和客户端解析 xml 文件占用大量资源且不易维护。 > **六、你在项目中用过哪些设计模式,分别是什么使用场景?** > **七、经典四表SQL题** > **八、编程题** 参考: ```Java import java.io.*; public class Copy04_复制一个文件夹 { /** * 当文件被打开时,不可以复制,所以说Workspaces复制不了,因为要用这个程序打开呢 * 测试过,可以实现 */ public static void main(String[] args) throws Exception{ String oldPath = "D:\\学习课件"; String newPath = oldPath.replaceFirst("D", "C");//将目标文件夹换成C盘,其它不变 copy_dir(new File(oldPath),new File(newPath)); } public static void copy_file(File srcFile,File targetFile) throws Exception{ //FileInputStream的构造方法: //public FileInputStream(File file) throws FileNotFoundException, //可以直接是File参数 BufferedInputStream bis = new BufferedInputStream(new FileInputStream(srcFile)); BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(targetFile)); int temp = 0;//开始复制 byte[] bytes = new byte[1024*1000]; while((temp = bis.read(bytes)) != -1){ bos.write(bytes, 0, temp); } bos.flush();//刷新 bos.close();//关闭 bis.close(); } public static void copy_dir(File srcDir,File targetDir) throws Exception{ if(!targetDir.exists()){ targetDir.mkdir();//如果不存在文件夹,创建 } File[] fs = srcDir.listFiles(); for(File ff:fs){//这个fs的长度就是结束条件 if(ff.isFile()){//是文件的话,要创建一个空白文件呢,copy_file是直接调用文件名 copy_file(new File(srcDir+"\\"+ff.getName()),new File(targetDir+"\\"+ff.getName())); }else{ copy_dir(new File(srcDir+"\\"+ff.getName()),new File(targetDir+"\\"+ff.getName())); //如果是文件夹也要创建一个新的文件,因为要使文件夹依次递进 } } } } ``` Last modification:February 22, 2023 © Allow specification reprint Like 0 喵ฅฅ
One comment
你写得非常清晰明了,让我很容易理解你的观点。