Loading... 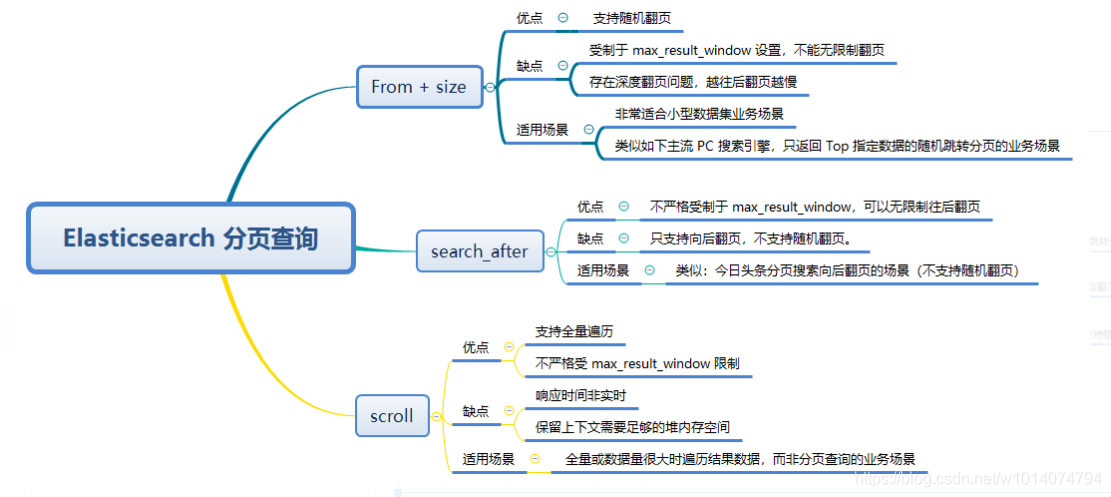 在说这三种分页查询方式之前先来探讨一下,为什么所有分布式存储系统都对深度分页的支持如此不友好呢? 假设一个存放私信的索引有6个分片,私信后台要根据筛选条件查询 50条/页 的数据,那么每个分片都要先查找出结果添加到 `50 * page + 50`大小的本地优先队列中,再把 **_id** 和 **排序值** 汇总给协调节点的优先队列,排序后得出这50条。 如果是101页,每页100条,那就是6个分片查10100条,再排序汇总后返回,效率可想而知。 ## 一、From + Size **复杂度:** 时间复杂度 `O(n)`、空间复杂度 `O(n)` **适用场景:** 适用于业务上通用的分页查找,随机调整不同的分页,查询在 `max_result_window`10000范围以内。(from+size超过10000es会报错,建议在查询es前做判断) 一般只需要通过写sql(... limit n, m)转DSL即可。 **优化建议:** 对于业务上需要按时间排序分页,且索引中不存在复杂类型,可以使用**索引排序**来优化查找速率。 ## 二、Scroll 原理: 对查询结果生成历史快照,返回时会带上类似MySQL中的游标 `scorll_id(ES5开始保持不变)`,后续通过游标去拉取数据直至返回 `hits`为空:query阶段同上,在fetch阶段 适用场景: 适用于遍历大量数据,用于非实时的批处理。 Last modification:September 9, 2022 © Allow specification reprint Like 0 喵ฅฅ