Loading... 近期学习《Redis深度历险》,打算将从中学到的分为:**方法原理+应用场景Demo**输出。 顺便也把书中一些目前还不太懂的地方插个眼,方便后续补上。 --- ## 一、分布式锁 分布式锁本质上要实现的目标就是在 Redis 里面占一个“茅坑”,当别的进程也要来占时,发现已经有人蹲在那里了,就只好放弃或者稍后再来。 占坑一般是使用 `setnx`(set if not exists) 指令,只允许被一个客户端占坑。先来先占, 用完了,再调用 `del` 指令释放茅坑。 尽管Redis 2.8中加入了原子性的setnx+expire:`set name zhangsan ex 100 nx`。但仍需要考虑到超时续命、可重入性等问题。 [redis分布式锁的各种坑](https://blog.csdn.net/qq_36794621/article/details/104883953)这篇文章讲的就是**一步步从单机redis蜕变到Redisson**,一目了然。 既然提到了Redisson,就指正下上篇[Redis入门篇](http://www.tangsong.fun/index.php/Redis1.html)中的点: RedisTemplate/StringRedisTemplate算是老技术了,只不过因为整合Redis简单,入手快,所以很多项目中一直沿用至今。 经历Jedis、Lettuce的过渡,个人觉得还是使用最新的Redisson更好。 以下对比来自[redisTemplate、jedis、lettuce、redission的对比](https://blog.csdn.net/qq_40925189/article/details/109580439): 1. `RedisTemplate`是基于某个具体实现的再封装,比如说SpringBoot1.x时,具体实现是Jedis;而到了SpringBoot2.x时,具体实现变成了Lettuce。 优点是基于SpringBoot自动装配的原理,隐藏了具体的实现,使得整合Redis时比较简单。缺点是效率慢,有人测试过**Jedis效率要10-30倍的高于RedisTemplate的执行效率**。 2. `Jedis`作为老牌的Redis客户端,**采用同步阻塞式IO,采用线程池时是线程安全的。** 优点是简单、灵活、api全面。缺点是某些Redis高级功能需要自己封装。 3. `Lettuce`作为新式的Redis客户端,**基于Netty,采用异步非阻塞式IO,是线程安全的。** 优点是提供了很多Redis高级功能,例如集群、哨兵、管道等。缺点是API抽象,学习成本高。Lettuce好是好,奈何Jedis比他生得早。 4. `Redission`作为Redis的**分布式**客户端,同样**基于netty采用异步非阻塞式IO,是线程安全的。** 优点是提供了很多Redis的分布式操作和高级功能,缺点是API抽象,学习成本高(除分布式锁外的其它教程少之又少)。 **综上所述,单机并发量低时优先选择Jedis,分布式高并发时优先选择Redission。** 顺带一提,最近新接触的中台架构中对于Redis这块的规约如下: > 1.1 关于分布式缓存已集成 `jetCache`,开发使用可参考 [这里](https://github.com/alibaba/jetcache/wiki/Home_CN) 注意:如果参数是对象,那么需要保证参数对象的属性在方法在业务代里没有被修改,否则会存在缓存无法命中的问题 > 1.2 关于分布式锁已集成 `redisson`,可用 `@RedissonLock`注解在方法上按输入参数和实际业务判断是否跳过不处理,是否锁整个方法,码块可参考 `@RedissonLock`此注解写法 > 1.3 统一使用 `jetCache`作为缓存客户端,支持本地缓存(一级缓存)和远程缓存(二级缓存),支持方法注解 `@Cached`缓存方式和手动api调用方式,注解方式为主,手动api调用为辅,手动缓存命名规则为"服务名称:服务模块:业务归属唯一标识ID" > 1.4 对于需要redis客户端命令的原生操作,`jetCache`支持 `Lettuce`异步非阻塞,统一用 `RedisCommands` 但就jetCache而言,它更适合最简单的缓存场景,通过注解一步到位。在实际开发过程中遇到一些不可描述的问题,并且已经很长时间没有维护了。个人建议还是直接使用Redission作为Redis操作工具。 ## 二、延时队列 ### 方法原理 延时队列的理解可以看这里:[你知道Redis可以实现延迟队列吗?](https://www.cnblogs.com/xiaowei123/p/13222710.html) 延时队列可用Redis的 `zset`来实现。Redis充当延时队列的好处在于,它不像Rabbitmq、Kafka那样有一堆繁琐的特性和步骤。坏处在于其实现 ack 机制的成本相对较高,不适用于极致追求可靠性保障。 **Redis可用于延时队列的优势:** (1)Redis zset支持高性能的 score 排序。 (2)Redis是在内存上进行操作的,速度非常快。 (3)Redis可以搭建集群,当消息很多时候,我们可以用集群来提高消息处理的速度,提高可用性。 (4)Redis具有持久化机制,当出现故障的时候,可以通过AOF和RDB方式来对数据进行恢复,保证了数据的可靠性 ### 应用场景 <div class="preview"> <div class="post-inser post box-shadow-wrap-normal"> <a href="http://www.tangsong.fun/index.php/Redis-RateLimit.html" target="_blank" class="post_inser_a no-external-link no-underline-link"> <div class="inner-image bg" style="background-image: url(https://blog-picture01.oss-cn-shenzhen.aliyuncs.com/img/20211014145810.JPG);background-size: cover;"></div> <div class="inner-content" > <p class="inser-title">HandlerInterceptor + Redis 限流</p> <div class="inster-summary text-muted"> 一、HandlerInterceptor拦截器public interface HandlerIntercepto... </div> </div> </a> <!-- .inner-content #####--> </div> <!-- .post-inser ####--> </div> ## 三、位图 ## 四、HyperLogLog ## 五、布隆过滤器 ### 方法理论 布隆过滤器可以理解为一个不怎么精确的 `set` 结构,当你使用它的 `contains` 方法判断某个对象是否存在时,它可能会误判:**它说值存在时,这个值不一定存在;但它说值不存在时,那么这个值一定不存在。** 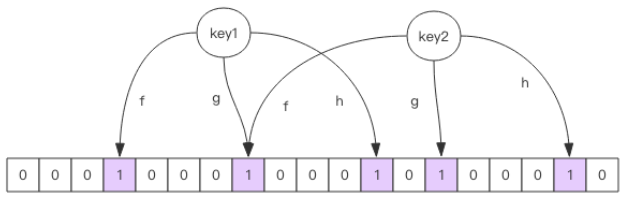 布隆过滤器在Redis的数据结构相当于**一个大型位数组+多个能把hash算得比较均匀的无偏hash函数**。 当一个key需要加入时,会经过这多个hash函数,在它们映射的位置上置为 `1`。所谓的误判也就是当某个key1映射后为 `1`的点位全部包含在key2中,那么key1会被判断为存在。  上图公式中:`l`为**位数组长度**,`n`为**预计元素数量**,`k`**最佳hash函数数量**,`f`为**错误率**。 **不要让实际元素远大于初始化大小。**如果实际元素超出较多,会导致误判率变大,需要重建一个 size 更大的过滤器,再将所有的历史元素批量 add 进去 (这就要求我们在其它的存储器中记录所有的历史元素)。 不过这种头疼的时候也有网站帮我们算好了,只需要输入预计元素和错误率就能得出大致的占用空间了。(以10w日活数据,错误率为0.005%,只占用了250KB,洒洒水啦~) ### 应用场景 一、爬虫中,通过布隆过滤掉爬过的URL。 二、NoSQL领域中,如HBase、Cassandra、LevelDB、RocksDB等内部都存在布隆过滤器结构以减少数据库的IO请求。 三、邮箱系统的垃圾邮件过滤。(邮件被丢到垃圾箱了大概率是这种误判) 四、凌晨结算前天日活用户、当天注册-激活用户。 **简单使用:** ```xml // 需要提前拉取镜像 > docker pull redislabs/rebloom # 拉取镜像 > docker run -p6379:6379 redislabs/rebloom # 运行容器 > redis-cli # 连接容器中的 redis 服务 bf.add // 添加 bf.madd // 批量添加 bf.exists // 查询是否存在 bf.mexists // 批量查询是否存在 ``` **基于Redison的当日激活-注册判断:** ```java @RunWith(SpringRunner.class) @SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT, classes = RiskControlApplication.class) public class RedisTest { @Autowired private RedissonClient redissonClient; @Test public void testBloomFilter() { String token = "test-token-001"; String token2 = "test-token-002"; String key = RedisKeyConstant.TODAY_REGISTER_TOKEN.setArg(DateUtil.today()); RBloomFilter<String> bloomFilter = redissonClient.getBloomFilter(key); // 不存在则新建,并设置25h过期 if (!bloomFilter.isExists()) { bloomFilter.tryInit(100000L, 0.0005); bloomFilter.expire(25, TimeUnit.HOURS); } bloomFilter.add(token); System.out.println(bloomFilter.contains(token)); System.out.println(bloomFilter.contains(token2)); } @Test public void testBloomFilter2() { String token = "test-token-001"; String token2 = "test-token-002"; String key = RedisKeyConstant.TODAY_REGISTER_TOKEN.setArg(DateUtil.yesterday().toDateStr()); RBloomFilter<String> bloomFilter = redissonClient.getBloomFilter(key); System.out.println(bloomFilter.isExists()); // 如果不存在,会报错 if (bloomFilter.isExists()){ System.out.println(bloomFilter.contains(token)); System.out.println(bloomFilter.contains(token2)); } } } ``` **暗坑**: `redissonClient.getBloomFilter(key, new StringCodec());`中的 `StringCodec()`默认指定成 `UTF-8`编码,而 `getBloomFilter(key)`却不会将key转成 `UTF-8`,两者的编码方式不同。如果写入的时候带了 `new StringCodec()`,读取的时候没带,那么 `RBloomFilter`还是会被判断成**存在**,但是** `contains()`会返回 `false`**找不到。 ### 布隆之上—布谷鸟过滤器 先说总结:**布谷鸟过滤器只会选用两个特殊的 hash 函数,算出两个位置p1、p2,但是每个位置可以放置多个座位,里面存放元素的 `指纹`。当p1位置上的指纹被挤兑之后,它可以根据p1和指纹计算出另一个 `对偶`p2的位置。** 布谷鸟过滤器中只会存储元素的指纹信息(几个bit,类似于布隆过滤器)。这里过滤器牺牲了数据的精确性换取了空间效率。正是因为存储的是元素的指纹信息,所以会存在误判率,这点和布隆过滤器如出一辙。 原文地址:[Redis布隆过滤器与布谷鸟过滤器](https://www.cnblogs.com/Courage129/p/14337466.html) (PS:100% Copy人家文章还在图片上加水印的公众号是真的屑,点名匠心零度,老子迟早给你取关) 数字指纹指纹这块拿[这个](https://cloud.tencent.com/developer/news/210454)凑合这看,非对称那块还给人家写错了,应该是要把公钥广播出去。建议[非对称加密](https://baike.baidu.com/item/%E9%9D%9E%E5%AF%B9%E7%A7%B0%E5%8A%A0%E5%AF%86/9874417)看度娘。 不过目前的主流还是布隆过滤器,一般的业务场景也是够用了。 `CuckooFilter`目前最多的是[Go实现](https://github.com/seiflotfy/cuckoofilter),Java实现可以看看[这个](https://github.com/MGunlogson/CuckooFilter4J) Last modification:August 22, 2022 © Allow specification reprint Like 0 喵ฅฅ
One comment
那如果死锁了一直没解呢,那不就凉了