Loading... 其实性能调优是一个十分复杂过程,其贯穿于应用开发的不同阶段。本文主要以数据库相关部分的调优来讲解。 [1]: http://www.tangsong.fun/usr/uploads/2020/12/2687047892.png <!--more--> 最好的调优方式就是从上游扼杀掉需要调优的地方,所以设计规范尤为重要,可以参考上一篇。 <div class="preview"> <div class="post-inser post box-shadow-wrap-normal"> <a href="http://www.tangsong.fun/index.php/MySQL-Development-Norms.html" target="_blank" class="post_inser_a no-external-link no-underline-link"> <div class="inner-image bg" style="background-image: url(http://www.tangsong.fun/usr/uploads/2020/12/1190492039.jpg);background-size: cover;"></div> <div class="inner-content" > <p class="inser-title">[MySQL]开发规范的二三事</p> <div class="inster-summary text-muted"> 本篇内容主要是按照整体设计、字段设计、索引设计以及SQL书写规范四个方面讲解了MySQL的开发规范,以及最后的My... </div> </div> </a> <!-- .inner-content #####--> </div> <!-- .post-inser ####--> </div> ## 一、MySQL数据库 ### MySQL版本 除了包含emoji表情非8.x的utf8mb4不可外,主要是用5.x版本: 其中 `5.0——5.1`是早期产品的延续和升级维护,只有非常非常老的大项目还在维持着。 而一般用的是 `5.4——5.x`,因为5.4及之后MySQL整合了三方公司的新存储引擎**(推荐5.5)** > 因为Windows下对MySQL的很多命令支持非常不友好,Windows下可以考虑直接用 `NaviCat for MySQL`。 > 本次实际操作是在阿里云的 `CentOS 7.6.1810`上进行,数据库版本为 `MySQL5.5.62` ### MySQL相关信息与配置 **(1)通过 `ps -ef|grep mysql`查看mysql所有进程信息** ```mysql # mysqld_safe是服务端工具,用于监听、启动mysqld,是mysqld的守护进程。 /www/server/mysql/bin/mysqld_safe # 数据库目录 --datadir=/www/server/data # 进程ID文件目录 --pid-file=/www/server/data/iZj6c6sknqd1yahy93cgpfZ.pid # 定义mysql支持的sql语法,分别表示:防止GRANT自动创建新用户,除非还指定了密码、如果需要的存储引擎被禁用或未编译,那么抛出错误(不设置此值时,用默认的存储引擎替代,并抛出一个异常。)。 --sql-mode=NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION # mysqld是mysql的核心程序,用于管理mysql的数据库文件以及用户的请求操作。 /www/server/mysql/bin/mysqld # mysql安装目录 --basedir=/www/server/mysql # 数据库目录 --datadir=/www/server/data # 数据库插件存放目录 --plugin-dir=/www/server/mysql/lib/plugin # 用户名 --user=mysql # 定义mysql支持的sql语法,分别表示:防止GRANT自动创建新用户,除非还指定了密码、如果需要的存储引擎被禁用或未编译,那么抛出错误(不设置此值时,用默认的存储引擎替代,并抛出一个异常。)。 --sql-mode=NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION # 错误日志记录目录 --log-error=iZj6c6sknqd1yahy93cgpfZ.err # mysqld能够打开的文件的数量最大值。 --open-files-limit=65535 # pid文件目录 --pid-file=/www/server/data/iZj6c6sknqd1yahy93cgpfZ.pid # 用于本地连接的Unix套接字文件 --socket=/tmp/mysql.sock # 端口号,用来帧听TCP/IP连接。端口号必须为1024或更大值,除非MySQL以root系统用户运行 --port=3306 # linux下当前显示文件颜色对应的类型 --color=auto mysql ``` **(2)MySQL配置文件信息** MySQL5.5 默认配置文件 `/etc/my.cnf` MySQL5.6 默认配置文件 `/etc/mysql-default.cnf` ```mysql [client] #password = your_password port = 3306 socket = /tmp/mysql.sock [mysqld] port = 3306 socket = /tmp/mysql.sock datadir = /www/server/data default_storage_engine = InnoDB skip-external-locking key_buffer_size = 32M max_allowed_packet = 100G table_open_cache = 128 sort_buffer_size = 768K net_buffer_length = 4K read_buffer_size = 768K read_rnd_buffer_size = 256K myisam_sort_buffer_size = 8M thread_cache_size = 16 query_cache_size = 16M tmp_table_size = 32M #skip-name-resolve max_connections = 500 max_connect_errors = 100 open_files_limit = 65535 log-bin=mysql-bin binlog_format=mixed server-id = 1 expire_logs_days = 10 slow_query_log=1 slow-query-log-file=/www/server/data/mysql-slow.log long_query_time=3 #log_queries_not_using_indexes=on innodb_data_home_dir = /www/server/data innodb_data_file_path = ibdata1:10M:autoextend innodb_log_group_home_dir = /www/server/data innodb_buffer_pool_size = 128M innodb_log_file_size = 64M innodb_log_buffer_size = 16M innodb_flush_log_at_trx_commit = 1 innodb_lock_wait_timeout = 50 innodb_max_dirty_pages_pct = 90 innodb_read_io_threads = 1 innodb_write_io_threads = 1 [mysqldump] quick max_allowed_packet = 500M [mysql] no-auto-rehash [myisamchk] key_buffer_size = 32M sort_buffer_size = 768K read_buffer = 2M write_buffer = 2M [mysqlhotcopy] interactive-timeout ``` 这些配置作用以后再讲 **(3)拿到之后把MySQL的默认编码全部统一为 `utf8mb4`** 查看编码:`show variables like '%char%'`  如果没统一就添加编码:`vi /etc/my.cnf` ```cnf [mysql] default-character-set=utf8mb4 [client] default-character-set=utf8mb4 [mysqld] character_set_server=utf8mb4 character_set_client=utf8mb4 collation_server=utf8_general_ci ``` 重启后生效(`service mysql restart`),且只对“之后”创建的数据库生效。所以建议在MySQL安装完毕后,第一时间统一编码。 ### MySQL逻辑分层  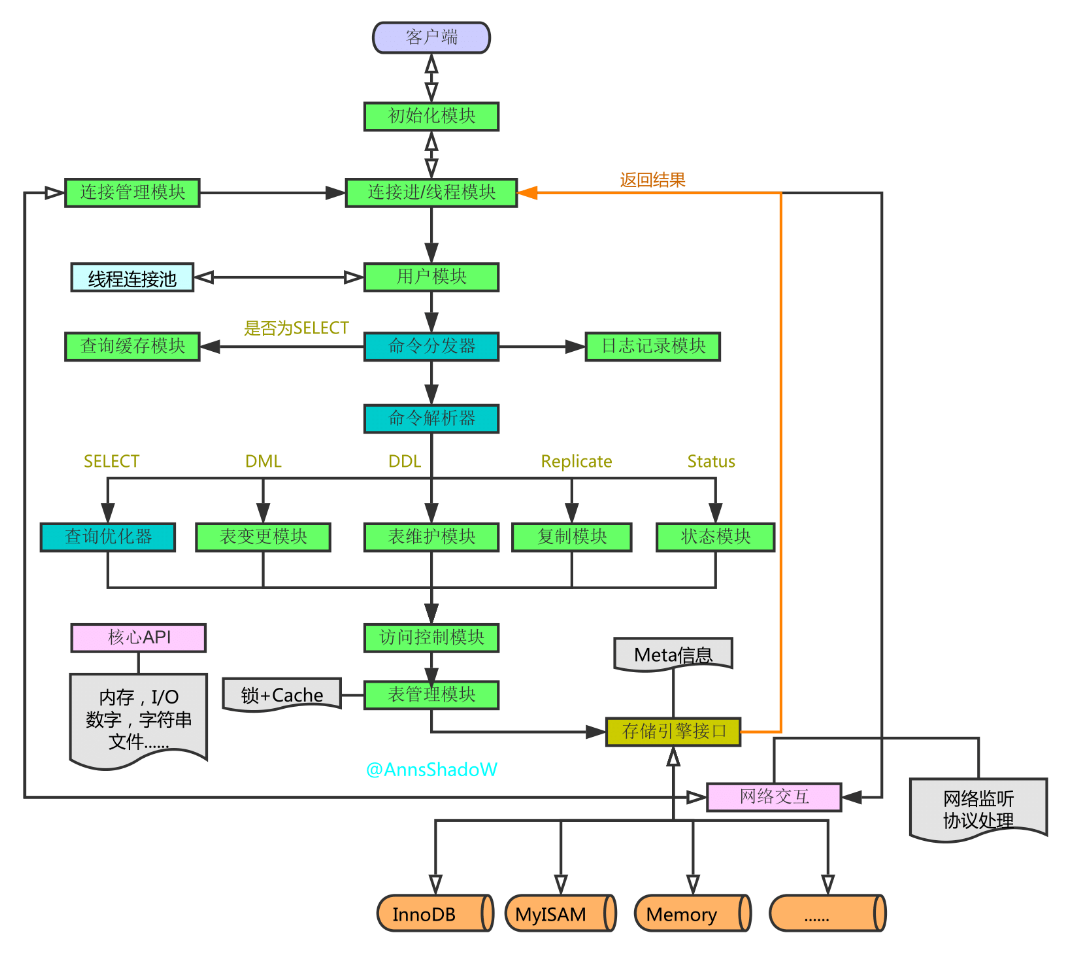 **(1)连接层:** 提供与客户端连接的服务,把连接请求丢给下面处理。 **(2)服务层:** 1.提供各种用户使用的接口(如:CRUD),调用接口去执行客户端传过来的sql。 2.提供SQL优化器(MySQL Query Optimizer),客户端传的sql太烂的话会导致优化器看不下去直接帮你做了优化,缺点是可能造成不一致问题。 **(3)引擎层:** 提供了各种存储方式,主要是InnoDB、MyISAM。 * InnoDB(默认) :事务优先(适合高并发操作;行锁) * MyISAM :性能优先(表锁)   **(4)存储层** 真正操作数据的地方。 ## 二、SQL调优 ### 原因 主要原因就是性能低(多绕弯)、执行/等待时间太长(慢日志可看)、SQL语句欠佳(连接查询)、索引失效、服务器参数设置不合理(线程数、缓存) ### SQL性能优化 | **语法顺序↓** | **执行顺序↓** | | ------------------------------------- | ------------------------------------- | | **select [distinct]** | from | | from | on | | **join(left/right/inner join)** | **join(left/right/inner join)** | | on | where | | where | group by | | group by | having | | having | **select [distinct]** | | union | union | | order by | order by | | limit | limit | MySQL执行顺序示例分析: ```sql # from .. on .. join .. where .. group by .. having .. select dinstinct .. union .. order by .. limit # 学生中有2个zs、3个ls select s.s_name from student s where s.s_name='zs' or s.s_name='ls'; # 解析过程一:from找到student表,where找到符合条件的记录,最后select出指定字段 select distinct s.s_name from student s where s.s_name='zs' or s.s_name='ls'; # 解析过程一(番外):select屁股后面紧挨着distinct select s.s_name,count(*) as '重名数' from student s where s.s_name='zs' or s.s_name='ls' group by s.s_name; # 解析过程二:先执行from、where,再执行group by,紧接着执行count()这类的聚合函数,select在后面 # 扩展,group by后面的字段在结果中是唯一的,所以不需要针对这个字段再distinct select s.s_name,count(*) as '重名数' from student s where s.s_name='zs' or s.s_name='ls' group by s.s_name having count(*) > 1; # 解析过程三:having是对group by中的表进行筛选,select在后面 # 扩展,如果zs、ls都是3个人,在这句select distinct后会变成一条数据,因为规则二下是对count(*)进行去重 select s.s_name,count(*) as 重名数 from student s where s.s_name='zs' or s.s_name='ls' group by s.s_name having count(*) > 1 union select s.s_name,count(*) as 重名数 from student s where s.s_name='ww' or s.s_name='ls' group by s.s_name ; # 解析过程四:union就是对两次select结果的合并,要求两次select的字段完全一致,默认去重。 select s.s_name,count(*) as 重名数 from student s where s.s_name='zs' or s.s_name='ls' group by s.s_name having count(*) > 1 union all select s.s_name,count(*) as 重名数 from student s where s.s_name='ww' or s.s_name='ls' group by s.s_name # 解析过程四(番外):保留重复用union all。 select s.s_name,count(*) as 重名数 from student s where s.s_name='zs' or s.s_name='ls' group by s.s_name having count(*) > 1 union select s.s_name,count(*) as 重名数 from student s where s.s_name='ww' or s.s_name='ls' group by s.s_name order by 重名数 asc; # 解析过程五:order by在union之后,对union之后的临时表进行排序操作,并且`order by 别名字段`如果是中午别名一定不能加单引号,上面select属性别名后面单引号可加可不加(别名如果是关键词必须加) select s.s_name,count(*) as 重名数 from student s where s.s_name='zs' or s.s_name='ls' group by s.s_name having count(*) > 1 union select s.s_name,count(*) as 重名数 from student s where s.s_name='ww' or s.s_name='ls' group by s.s_name order by 重名数 asc limit 2; # 解析过程六:limit在最后,取出数据中的前n条记录。 select s.s_name,count(*) as 重名数,st.t_id from student s left join stu_tea st on s.s_id=st.s_id where s.s_name='zs' or s.s_name='ls' group by s.s_name,st.t_id having count(*) > 1 union select s.s_name,count(*) as 重名数,st.t_id from student s left join stu_tea st on s.s_id=st.s_id where s.s_name='ww' or s.s_name='ls' group by s.s_name,st.t_id order by 重名数 asc limit 2; # 解析过程七:join on是在from之后根据on指定的条件把指定的表格数据附在from指定的表格后面,再执行相应的where...等操作 ``` ### 性能诊断 `explain + SQL语句`,进行模拟SQL优化器进行分析SQL的执行计划  | 字段 | 含义 | | ------------- | ---------------------- | | id | 编号 | | select_type | 查询类型 | | table | 表 | | type | 类型 | | partitions | 分区命中情况(5.7后) | | possible_keys | 预测用到的索引 | | key | 实际用到的索引 | | key_len | 实际索引的长度 | | ref | 表之间的引用 | | rows | 通过索引查询到的数据量 | | Extra | 额外的信息 | | filtered | 匹配数据的百分占比 | **(1)id** id代表执行编号,有优先级。id值**相同**时从上往下**顺序**执行,id值**不同**时id值**越大越优先**查询。 其本质是在嵌套子查询时,先查内层再查外层。 但是表的执行顺序会因表的数据量而改变,因为是按照笛卡尔积来计算临时表的大小的,(如:`4*3*2`和 `2*3*4`,中间临时表的大小为12和6,差了两倍。) **小表驱动大表**的原理,也正是因为如此。 ```sql # 查询教授SQL课程的老师的描述 explain select tc.tcdesc from teacherCard tc,course c,teacher t where c.tid = t.tid and t.tcid = tc.tcid and c.cname = 'sql' ; explain select tc.tcdesc from teacherCard tc where tc.tcid = (select t.tcid from teacher t where t.tid = (select c.tid from course c where c.cname = 'sql') ); explain select t.tname ,tc.tcdesc from teacher t,teacherCard tc where t.tcid= tc.tcid and t.tid = (select c.tid from course c where cname = 'sql') ; ```  table的显示顺序是按照 `where`字段后面表的出现顺序来的,优先级id则是按照先内再外。 **(2)** ## 三、索引优化 SQL优化主要就是针对索引优化。 索引相当于书本的目录,是帮助数据库高效获取数据的数据结构。可以是B树(默认)、Hash树。 索引实际上也是一种表,保存着主键或索引字段,以及一个能将每个记录指向实际表的指针。 增删操作在有索引的表中执行会花费更多时间,因为数据库也需要动态更改索引值。 **索引的优点** 1. 提高查询效率,降低IO使用率(客户端到服务端)。 2. 降低CPU使用率。(B数索引本身就是一个排序结构,因此order by的话只需要走中序遍历就能排出来) **索引的缺点** 1. 索引本身很大,需要占用一定的硬盘空间(内存也可但要配置) 2. 不是索引情况都能适用索引,如:少量数据、频繁更新/很少使用的字段等等 3. 索引会降低增删改的效率,因为每次修改都需要动态维护索引。 **索引分类** 索引可以分为唯一索引、单值(普通)索引、主键索引、复合(组合)索引和全文索引。 * **主键索引(PROMARY KEY)**:不能相同值、值不为NULL * **唯一索引(UNIQUE)**:不能相同值、值可为NULL、`uk_xxx` * **单值索引(INDEX)**:可以相同值、值可为NULL、`idx_xxx` * **复合索引(COMPOUND)**:多个单值索引,相当于多级目录,列值组合必须唯一 * **全文索引(FULLTEXT)**:可以针对多内容值中的某个单词,但效率不佳 **索引相关SQL** (1)创建索引 ```sql 方式一:create 索引类型 索引名 on 表(字段) # 单值: create index idx_name on tb(name[length]); # 唯一: create unique index uk_name on tb(name[length]); # 复合: create index idx_dept_name on tb(dept,name); 方式二:alter table 表名 索引类型 索引名(字段) # 主键: alter table tb add primary key (id) ; # 单值: alter table tb add index idx_dept(dept) ; # 唯一: alter table tb add unique index uk_name(name[length]); # 复合: alter table tb add index idx_dept_name(dept,name); ``` 附:length可以省略、指定表的主键时会默认创建主键索引 (2)删除索引 ```sql 方式一:drop index 索引名 on 表名; # 单值/复合/唯一/主键: drop index idx_name on tb; 方式二:alter table 表名 drop 索引类型 索引名; # 单值/组合/唯一: alter table tb drop index idx_name; # 主键: alter table tb drop primary key ; ``` (3)查询索引 ```sql show index from tb; show index from tb \G; ``` `\G`是在cmd上查看时的格式化输出,方便查看。 ### 避免索引失效原则、索引优化 * 复合索引,不要跨列使用或无序使用(最佳左前缀) * 复合索引,尽量使用全索引匹配 * 不要再索引相关字段上进行任何操作(计算、函数、类型转换),这都会导致索引失效。 复合索引,如果左边失效,则右边全部失效。 ## 四、单表/多表优化范例 ## 五、其它优化方法 ## 六、慢查询日志的SQL排查 ## 七、海量数据分析 ## 八、锁机制 ## 九、主从复制 Last modification:August 19, 2022 © Allow specification reprint Like 0 喵ฅฅ
One comment
期待